
Page 190 - 《爆炸与冲击》2026年第5期
P. 190
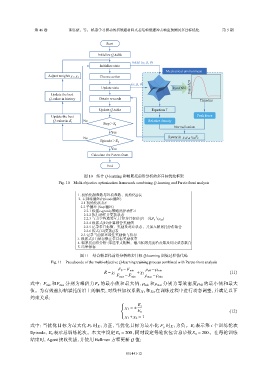
第 46 卷 韩思豪,等: 机器学习驱动的折纸超材料夹芯结构低速冲击响应预测及多目标优化 第 5 期
Start
Initialize Q-table
Initial (α, β, θ)
Initialize state
Mechanical environment
Adjust weights χ 1 , χ 2 Choose action
(α, β, θ)
Update state ResANN Force/kN
Update the best
Q-value in history Obtain rewards Time/ms
Update Q-table Equation 7
Update the best Peak force
No Relative density
Q-value in E i
Step>S 0
Normalization
Yes
No Rewards=χ 1 ρ eff +χ 2 F P
Episode>E 0
Yes
Calculate the Pareto front
End
图 10 结合 Q-learning 和帕累托前沿分析的多目标优化框架
Fig. 10 Multi-objective optimization framework combining Q-learning and Pareto front analysis
1. 初始化超参数与环境参数,初始化Q表
2. 主训练循环(Episode循环)
2.1 初始化状态S
2.2 子循环 (Step循环)
2.2.1 根据ε-greedy策略选择动作A
2.2.2 执行动作并更新状态
2.2.3 与力学环境交互,计算多目标值(归一化F P 与ρ eff )
2.2.4 根据式(10)计算综合奖励值
2.2.5 记录多目标值、奖励及对应状态,并加入帕累托分析集合
2.2.6 按式(12)更新Q表
2.3 记录当前循环最佳奖励值与状态
3. 根据式(11)动态修正多目标奖励权重
4. 帕累托前沿分析: 筛选非支配解,输出帕累托前沿点集及对应状态集合
5. 结果保存
图 11 结合帕累托前沿分析的多目标 Q-learning 训练过程伪代码
Fig. 11 Pseudocode of the multi-objective Q-learning training process combined with Pareto front analysis
F P − F min ρ eff −ρ min
(11)
R = χ 1 +χ 2
F max − F min ρ max −ρ min
ρ eff 的最小值和最大
式中: F min 和 F max 分别为峰值力 F P 的最小值和最大值, ρ min 和 ρ max 分别为等效密度
χ 2 在训练过程中进行动态调整,并满足以下
值。为有效遍历帕累托前沿上的解集,对线性加权系数 χ 1 和
约束关系:
E i
χ 1 = ±
(12)
E 0
χ 1 +χ 2 = 1
χ 1 为正,当优化目标为最小化 p E i 表示第 i 个训练轮次
式中:当优化目标为最大化 F P 时 F 时 χ 1 为负。
S 0 = 200 。在每轮训练
Episode, E 0 表示总训练轮次。本文中设定 E 0 = 200 ,同时设定每轮次包含总步数
结束时,Agent 接收奖励,并使用 Bellman 方程更新 Q 值:
051441-12