
Page 189 - 《爆炸与冲击》2026年第5期
P. 189
α
α
α
α
ρ
β
β
β β α α β α β α α α
β
β
ρ
第 46 卷 韩思豪,等: 机器学习驱动的折纸超材料夹芯结构低速冲击响应预测及多目标优化 β第 5 期
β
θ=15°
18 0.258
16
0.256 θ=15° θ=32° Bending deformation Load
Force/kN 14 Effective density θ=32° in creases redistribution
12 0.254
Fracture
θ=15° θ=32°
10 0.252
16 20 24 28 32 Tensile/compressive deformation
in plates
θ/(°)
(h) Stress propagation
(g) Effect of θ on F P and ρ eff (i) Load redistribution for varying θ
path for varying θ
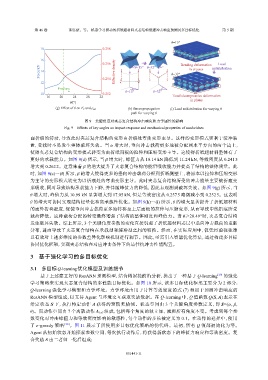
图 9 关键角度对夹芯复合结构冲击响应和力学属性的影响
Fig. 9 Effects of key angles on impact response and mechanical properties of sandwiches
面折痕的转动,导致此时夹芯复合结构的变形由折痕处弯曲变形主导。这样的变形模式更利于缓冲装
置,受载时不易发生整体破坏失效。当 α 增大时,垂向冲击载荷更多地被分配到水平方向的两个边上,
使得夹芯复合结构的变形模式转变为由折纸面板的拉伸和压缩变形主导。这使得折纸超材料整体有了
更好的承载能力。如图 9(d) 所示,当 β 增大时,峰值力从 18.14 kN 降低到 11.24 kN,等效密度从 0.241 5
增大到 0.262 2。这意味着 β 的增大提升了夹芯复合结构的能量吸收能力并提高了结构的整体质量。此
时,如图 9(e)~(f) 所示,β 的增大使得更多的垂向冲击载荷分配到折纸侧壁上,将原本以拉伸和压缩变形
为主导的变形模式转变为以折痕处的弯曲变形主导。此时夹芯复合结构所受的冲击能量主要被折痕变
形吸收,同时导致结构承载能力下降,并伴随峰值力的降低,因此未观测到破坏失效。如图 9(g) 所示,当
θ 增大时,峰值力从 10.99 kN 显著增大到 17.05 kN,但是等效密度从 0.257 5 略微减小到 0.252 5。这表明
θ 的增大可协同实现结构轻量化和高承载性优化。如图 9(h)~(i) 所示,θ 的增大显著提升了折纸超材料
的面外折叠程度,促使垂向冲击载荷更多地转移至上层面板的拉伸与压缩变形,从而导致中线折痕所受
载荷降低。这种载荷分配的转变最终增强了结构的整体刚度和峰值力。当 θ≥20.49°时,夹芯复合结构
发生破坏失效。综上所示,3 个关键角度参数的变化直接引起了折纸超材料芯层中垂向冲击载荷的重新
分布,进而导致了夹芯复合结构在承载型和缓冲型之间的切换。然而,在实际应用中,仅凭经验往往难
以有效对上述多维度的参数差异化影响机制进行调节。因此,亟需引入智能优化算法,通过构建多目标
协同优化框架,实现夹芯结构在对应冲击条件下的最佳抗冲击性能配置。
3 基于强化学习的多目标优化
Q-learning 优化模型及训练细节
3.1 多目标
基于上述建立好的 ResANN 预测模型,结合帕累托前沿分析,提出了一种基于 Q-learning [29] 的强化
学习策略来实现夹芯复合结构的多性能目标优化。如图 10 所示,该多目标优化框架主要分为 2 部分:
Q-learning 强化学习模型和力学环境。力学环境由用于计算等效密度的式 (7) 和用于预测冲击响应的
ResANN 模型组成,以支持 Agent 与环境交互获取奖励数据。在 Q-learning 中,Q 值函数 Q(S, A) 表示在
给定状态 S 下,执行特定动作 A 获得的预期奖励值。状态空间由 3 个关键角度参数定义,即 S=(α,β,
θ)。而动作空间由 7 个离散动作 A 1×7 组成,包括每个角度的独立加、减和所有角度不变。考虑到每个参
数变化对冲击峰值力和等效密度影响的敏感性,每个动作的步长被定义为 0.1。在动作的选择中,使用
了 ε-greedy 策略 [30] 。图 11 展示了所使用多目标优化策略的伪代码。最初,所有 Q 值都初始化为零。
Agent 从初始状态开始探索参数空间,每次执行动作后,将获得新状态下的峰值力响应和等效密度。复
合奖励 R 由二者归一化后组成:
051441-11