
Page 169 - 《振动工程学报》2026年第3期
P. 169
第 3 期 孟祥恒,等: 自编码器在机械设备未知故障检测中的应用 769
SDAEC 模型对各数据集的测试数据进行未知 了已知样本,导致最后只能将 IRF 分类为特征比较
故障检测的结果如表 3 所示,在数据集 1 中由于未知 相似的已知样本 ORF。数据集 2 中虽然部分未知
故障样本全部检测为已知样本,因此 PRE、REC 与 ORF 样本被检测出来,但是仍然有大部分被判断为
F1 的值全都为 0。在数据集 2 中,虽然 PRE 的值较 已知样本,这部分样本在分类过程中同样会被错误
高,但是由于正确检测的未知样本数量占全部未知 判断为已知的样本类型。在 SDAEC 模型下,数据
故障样本的比例并不高,所以 F1 值也较低。 集 1 已知样本的分类准确率为 49.6%,数据集 2 已知
样本的分类准确率为 63.6%,由于无法准确检测出
表 3 不同算法对未知故障检测的结果对比 未知故障样本导致对已知样本的分类准确率偏低。
Tab. 3 Comparison of unknown fault detection results by
different algorithms 因此对未知故障的检测能力将严重影响模型的
整体性能,为了进一步提高模型对未知样本的识别能
数据集 算法 ACC PRE REC F1
力,使用多解码器代替 SDAEC 模型中的单解码器,令
MDAEC 0.99 0.99 0.98 0.99
每 一 类 样 本 训 练 各 自 的 解 码 器 ,建 立 了 MDAEC
SDAEC 0.49 0 0 0
1 模型。
OCSVM 0.83 0.82 0.84 0.83
iForest 0.44 0 0 0 图 8 为数据集 1 的测试数据输入各解码器之后
MDAEC 0.98 0.96 1.00 0.98 得到的重构误差,由于此时解码器对不同类型样本
SDAEC 0.71 0.98 0.43 0.59 的敏感性增强,重构误差偏大,为了更好地观察重构
2
OCSVM 0.92 0.86 1.00 0.93 误差的相对大小,对重构误差取自然对数之后进行
iForest 0.43 0 0 0
绘图。其中,解码器 1 为已知的正常数据训练得到
的 ,解 码 器 2 为 已 知 的 ORF 样 本 训 练 得 到 的 。 从
当样本的重构误差小于阈值时,该样本为已知
图 8 中可以看出,数据集 1 中未知的故障样本的重构
样本,之后会将编码器得到的低维特征输入分类器
误差在每一个解码器的输出结果中基本都大于阈
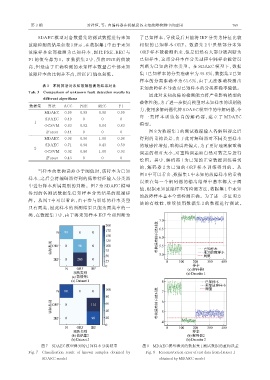
中进行样本所属类别的判断。图 7 为 SDAEC 模型
值,根据未知故障样本的检测方法,数据集 1 中未知
得到的各测试数据集已知样本分类结果的混淆矩
的故障样本基本全部检测正确。为了进一步证明方
阵。从图 7 中可以看出,由于参与训练的样本类型
法的有效性,继续使用数据集 2 的数据进行测试。
只有两类,因此样本的预测结果只能为两类中的一
类,在数据集 1 中,由于将未知样本 IRF 全部判断为
图 7 SDAEC 模型得到的已知样本分类结果 图 8 MDAEC 模型得到的数据集 1 测试数据的重构误差
Fig. 7 Classification result of known samples obtained by Fig. 8 Reconstruction error of test data from dataset 1
SDAEC model obtained by MDAEC model