
Page 108 - 《振动工程学报》2025年第11期
P. 108
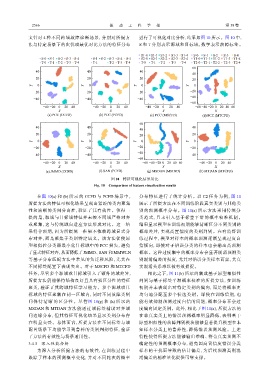
2566 振 动 工 程 学 报 第 38 卷
文针对 4 种不同跨域故障诊断场景,分别对所提方 进行了可视化对比分析,结果如图 10 所示。图 10 中,
法与特定场景下的次优或最优对比方法的特征分布 S 和 T 分别表示源域和目标域,数字表示故障标签。
S1-0 S1-1 S1-2 S1-3 S1-4 S-0 S-1 S-2 S-3 S-4
S-0 S-1 S-2 S-3 S-4 S-1 S-2 S-3 S-4 S-5 S2-0 S2-1 S2-2 S2-3 S2-4 T1-0 T1-1 T1-2 T1-3 T1-4
T-0 T-1 T-2 T-3 T-4 T-1 T-2 T-3 T-4 T-0 T-1 T-2 T-3 T-4 T2-0 T2-1 T2-2 T2-3 T2-4
60
40 40 40
40
20 20 20 20
Y 0 Y 0 Y 0 Y 0
−20 −20 −20 −20
−40
−40 −40 −40
−60
−40 −20 0 20 40 −40 −20 0 20 40 −40 −20 0 20 40 −60 −40 −20 0 20 40 60
X X X X
(a) PCC (CCFD) (b) PCC (PCFD) (c) PCC (MSCFD) (d) PCC (MTCFD)
60
40 40 40
40
20 20 20 20
Y 0 Y 0 Y 0 Y 0
−20 −20 −20 −20
−40
−40 −40 −40
−60
−40 −20 0 20 40 −40 −20 0 20 40 −60 −40 −20 0 20 40 60 −40 −20 0 20 40
X X X X
(e) JMMD (CCFD) (f) SAN (PCFD) (g) MSDAN (MSCFD) (h) MTDAN (MTCFD)
图 10 特征可视化结果对比
Fig. 10 Comparison of feature visualization results
在图 10(a) 和 (b) 所示的 CCFD 与 PCFD 场景中, 分布特征进行了统计分析。以 C2 任务为例,图 11
所提方法的特征可视化结果呈现出紧凑的类内聚集 展示了所提方法在不同训练阶段真实类别与其他类
性和清晰的类间分离性,验证了其有效性。值得一 别的预测概率分布。图 11(a) 所示方法采用传统分
提的是,源域与目标域特征并未按不同域严格对齐 类范式,且未引入基于标签平滑的概率校准机制。
或聚集,这与传统域自适应方法形成对比。这一结 结果显示模型在训练初期能够清晰区分不同类别的
果符合预期,因为所提统一框架不依赖跨域显式分 概率差异,实现高置信度的类别判别。在有监督训
布对齐,而是聚焦于类别特定语义。该方法促使原 练过程中,模型对样本的概率预测逐渐呈现过度自
型相似性分类器最小化目标域中的 PCC 损失,避免 信倾向,即使对于错误分类的样本也会输出高预测
了显式特征对齐,从而降低了 JMMD、SAN 和 MMWLN 概率。这种过度集中的概率分布会显著削弱预测类
等基于分布匹配方法中常见的负迁移风险,尤其在 别混淆偏差的强度,尤其对错误分类样本而言,其真
不同标签配置下表现突出。对于 MSCFD 和 MTCFD 实混淆关系难以被有效捕捉。
任务,尽管多个源域或目标域引入了额外的域差异, 相比之下,图 11(b) 所示的集成基于原型相似性
所提方法仍能保持结构良好且具有强区分性的特征 判别与基于标签平滑概率校准的所提方法,在训练
聚类,验证了其跨域特征学习能力。多个源域或目 初期并未表现出对特定类别的偏向,而是将概率更
标域的特征聚集在同一区域内,同时不同故障类别 均匀地分配至多个候选类别。即使在训练后期,也
间 保 持 清 晰 的 区 分 性 。 尽 管图 10(g) 和 (h) 所 示 的 能有效抑制预测过度自信的问题,概率分布不会过
MSDAN 和 MTDAN 方法能通过域标签辅助对齐域 度偏向固定类别。此外,相比于图 11(a),所提方法的
间边缘分布,但其特征可视化结果显示类别分布存 在非真实类上的错误预测概率明显降低,表明基于
在明显交叠。总体而言,所提方法在不同标签与域 原型相似性的故障判别模块能够显著提升模型在未
配置场景下均能学习到鲁棒的类别判别特征,验证 知样本分类上的鲁棒性,降低错误预测风险。上述
了方法的有效性与场景通用性。 特性使得所提方法能够输出准确、符合真实预测不
3.4.3 深入性能分析 确定性的预测概率分布,避免因高置信度错误分类
为深入分析所提方法的有效性,在训练过程中 样本的干扰而导致的估计偏差,为后续预测类别混
跟踪了样本的预测概率变化,并对不同轮次的概率 淆偏差的精准量化提供可靠支撑。