
Page 38 - 《软件学报》2025年第12期
P. 38
沈莉 等: swJulia: 面向新一代神威超级计算机的 Julia 语言编译系统 5419
综上所述, 借助于 SACA.jl, 我们能够在尽可能接近原始 SACA C 性能的同时, 享受到 Julia 语言带来的编程
便利性, 这使得使用 Julia 在神威新一代超级计算机上进行众核编程成为一种既便捷又高效的选择.
4.3 示范应用优化效果测试
本文基于 swJulia 实现了对量子化学模拟器 NNQS-Transformer 的支撑和优化. 一方面, 我们借助 swJulia 灵活
的众核加速方式, 对热点函数进行了充分的众核优化, 以提升模拟器在单 CPU 上的计算效率. 另一方面, 我们使
用 MPI.jl 实现了 NNQS-Transformer 在新一代神威超级计算机上的大规模可扩展并行模拟, 以充分继承原生 MPI
库针对神威硬件特性的定制优化.
在 SACA 编程模型中, 我们设计了一种全局共享执行模式, 从全芯片的角度实现众核加速编程. 为了最大化
资源利用率, 我们让每个 CPU 执行单个进程, 并赋予其对所有芯片资源的独占访问权限. 这包括整个 96 GB 的全
局共享内存空间以及处理器阵列中所有 384 个 CPE 的集体计算能力. 通过最小化每个 CPU 内部的进程间通信,
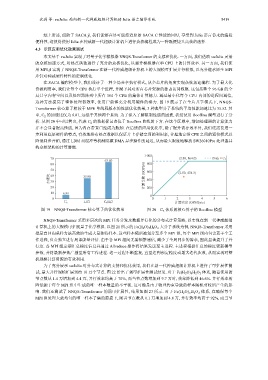
这种方法提高了整体处理器效率, 使用户能够充分利用硬件的潜力. 图 19 展示了在全片共享模式下, NNQS-
Transformer 核心算子相较于 MPE 单线程版本的性能优化效果, 3 种典型分子系统的平均性能加速比为 35.52. 其
中, C 2 的加速比仅为 6.81, 远低于其他两个系统. 为了深入了解限制性能的因素, 我们使用 Roofline 模型进行了分
析. 从图 20 中可以看出, 代表 C 2 的数据标记点位于 Roofline 曲线的下方. 在这个区域中, 增加处理器的计算能力
并不会显著提高性能, 因为内存带宽已经成为瓶颈. 在后续的应用优化中, 除了提升访存效率外, 我们还需要进一
步利用底层硬件的特点, 有效地排布热点数据以保证片上存储空间的利用率, 合理地安排 CPE 之间的通信模式以
降低同步开销, 通过 LDM 双缓冲等机制隐藏 DMA 异步操作的延迟, 从而最大限度地释放 SW26010Pro 处理器异
构众核架构的计算潜能.
1 000
70 (2.88, 864.0) Peak C 2
63.80
60 800
50 600 (2.50, 478.3)
加速比 40 35.96 计算性能 (GOPS/s) 400
30
20 200
10 6.81
0
0 0 1 2 3 4 5 6
LiCl C 2 H 4 O
C 2 计算密度 (OPS/Byte)
图 19 NNQS-Transformer 核心算子的优化效果 图 20 C 2 体系的核心算子的 Roofline 模型
NNQS-Transformer 采用多层次的 MPI 任务分发及数据并行化的分布式计算策略, 以实现在新一代神威超级
计算机上的大规模可扩展量子化学模拟. 以图 21 所示的 Fe(H 2 O) 5 H 2 O 2 大分子系统为例, NNQS-Transformer 采用
批量自回归采样方法高效地生成大量独特样本. 这些样本随后被划分至多个 MPI 组, 每个 MPI 组内包含若干个工
作进程, 负责独立进行局部能量评估. 由于各 MPI 组间无需频繁通信, 减少了全局同步的需求, 因此显著提升了并
行度. 各 MPI 组定期汇总梯度信息并通过 Allreduce 操作将结果发送至主进程. 主进程根据汇总的梯度更新模型
参数, 并将最新参数广播至所有工作进程. 这一过程不断重复, 直至达到预定精度或最大迭代次数, 从而实现对整
机规模计算资源的有效利用.
为了充分展示 swJulia 对分布式计算的支持和优化效果, 我们在新一代神威超级计算机上进行了可扩展性测
试, 最大并行规模扩展到约 10 万个节点. 图 22 给出了强可扩展性测试结果. 对于 Fe(H 2 O) 5 H 2 O 2 体系, 随着使用的
节点数从 1.4 万增加到 4.4 万, 并行效率均高于 70%, 而当节点数增加到 9.7 万时, 效率降低到 46.6%. 并行效率的
降低源于每个 MPI 组中生成的唯一样本数量的不平衡, 这可能是由于物理约束导致的样本随机剪枝所产生的影
响. 我们还测试了 NNQS-Transformer 的弱可扩展性, 结果如图 23 所示. 对于 Fe(H 2 O) 5 H 2 O 2 体系, 在确保每个
MPI 组处理大致均匀的唯一样本子集的前提下, 随着节点数从 0.1 万增加到 4.8 万, 并行效率均高于 92%, 而当节