
Page 36 - 《软件学报》2025年第12期
P. 36
沈莉 等: swJulia: 面向新一代神威超级计算机的 Julia 语言编译系统 5417
时间难以全面反映 JIT 编译的性能. 本文通过对 Julia 函数首次执行时的 JIT 编译和垃圾回收时间占比等指标进行
分析, 能够有效屏蔽硬件差异性等影响因素, 从而较为准确地评估 MPE 编译器的性能.
Julia 在标准库中提供了@time 宏, 用于测量代码块的执行时间, 并统计编译和垃圾回收的时间占比. 本文使用
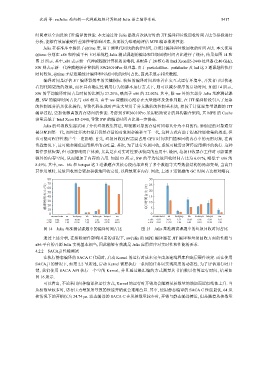
@time 分别在 x86 和神威平台上对单线程 Julia 测试课题的编译和垃圾回收时间占比进行了统计, 结果如图 14 和
图 15 所示. 其中, x86 表示新一代神威超级计算机的前端机, 其配备了 24 核心的 Intel Xeon E5-2440 处理器 (2.40 GHz),
SW 则表示新一代神威超级计算机的 SW26010Pro 处理器. 由于 particlefilter、pathfinder 及 lud 这 3 道课题的执行
时间较短, @time 无法准确统计编译和垃圾回收的时间占比, 因此未展示相关数据.
编译时间是评估 JIT 编译器效率的关键指标. 较短的编译时间意味着在交互式运行环境中, 开发者可以快速
看到代码更改的效果, 而在具有确定性调用行为的脚本运行方式下, 则可以减少程序的启动时间. 如图 14 所示,
SW 的平均编译时间占总时间的比例为 27.20%, 略高于 x86 的 22.02%. 其中, 除 nw 外的大部分 Julia 基准测试课
题, SW 的编译时间占比与 x86 相当. 由于 nw 课题核心段存在大量循环及条件判断, 在 JIT 编译阶段引入了复杂
的控制流分析及优化操作, 导致代码生成时产生大量用于分支跳转的控制基本块, 相较于计算密集型课题的 JIT
编译过程, 更加依赖离散内存访问的性能. 考虑到 SW26010Pro 采用精简设计的异构融合架构, 其 MPE 的 Cache
容量远低于 Intel Xeon E5-2440, 导致 SW 的编译时间占比进一步提高.
Julia 的垃圾收集器采用了分代垃圾收集算法, 即根据对象的存活时间将其分为不同的代. 新创建的对象通常
被分配到第一代, 而经过多次扫描后仍然存活的对象则会被移至下一代, 这种方式有助于提高垃圾收集的效率, 但
也可能对程序性能产生一定影响. 首先, 垃圾回收过程需要占用 CPU 时间来扫描和回收内存中的无用对象, 在高
负载情况下, 这可能会降低应用程序的吞吐量. 其次, 为了进行垃圾回收, 系统可能需要暂停应用程序的执行. 这种
暂停虽然短暂, 但可能影响用户体验, 尤其是在对实时性要求较高的应用中. 最后, 垃圾回收器在工作时可能需要
额外的内存空间, 从而增加了内存的占用. 如图 15 所示, SW 的平均垃圾回收时间占比为 6.07%, 略低于 x86 的
8.49%. 其中, nn、bfs 和 hotspot 这 3 道课题在其核心段内部声明了多个数组等大型数据结构的局部变量, 当离开
其作用域时, 垃圾回收器会更加积极地回收它们, 以释放更多内存. 因此, 上述 3 道课题的 GC 时间占比相对略高.
80 30
70 25
编译时间占比 (%) 50 GC 时间占比 (%) 20
60
15
40
30
10
20
10
0 5 0
streamcluster nn backprop bfs leukocyte hotspot nw streamcluster nn backprop bfs leukocyte hotspot nw
x86 0.02 0.04 70.98 3.45 7.21 69.76 2.65 x86 0.07 24.31 2.73 12.45 6.66 9.54 3.63
SW 0.02 1.09 62.56 3.99 10.98 65.76 46.01 SW 0.04 11.70 1.86 6.04 8.40 12.94 1.50
图 14 Julia 基准测试课题中的编译时间占比 图 15 Julia 基准测试课题中的垃圾回收时间占比
通过上述分析, 在排除硬件影响因素的前提下, swJulia 的 MPE 编译器在 JIT 编译和垃圾回收方面的性能与
x86 平台的开源 Julia 实现基本相当, 因此能够有效满足 Julia 应用程序对实时性和性能的要求.
4.2.2 SACA.jl 性能测试
在执行静态编译的 SACA C 代码时, 启动 Kernel 的运行时成本完全由加速线程库和底层硬件决定. 而在使用
SACA.jl 的情况下, 如第 2.2 节所述, 启动 Kernel 需要执行一系列的任务以实现高度的动态性. 为了评估运行时开
销, 我们使用 SACA API 执行一个空的 Kernel, 并且通过嵌汇编的方式测量其节拍数以估算运行时间, 结果如
图 16 所示.
可以看出, 不论采用何种编译和运行方式, Kernel 的运行时开销均会随着从核数量的增加而近似线性上升. 当
从核数量较多时, 访存压力增加所导致的性能开销就会逐渐凸显. 其中, 使用静态编译的 SACA C 性能最优, 64 从
核情况下的开销仅为 24.74 μs. 动态编译的 SACA C 在从核数量较少时, 开销与静态编译接近, 但是随着从核数量