
Page 37 - 《软件学报》2025年第12期
P. 37
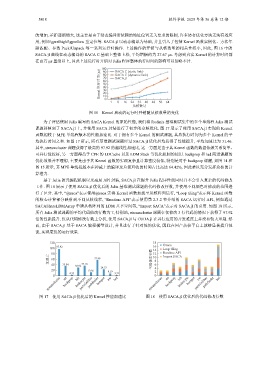
5418 软件学报 2025 年第 36 卷第 12 期
的增加, 差距逐渐增大, 这主要是由于动态编译所依赖的地址位置无关要求的限制, 许多访存优化方法无法有效应
用, 例如!gprelhigh/!gprellow 重定位等. SACA.jl 以动态编译为基础, 并且引入了包括 Kernel 函数实例化、方法年
龄匹配、参数 Pack/Unpack 等一系列运行时操作. 上述操作的开销与从核数量的相关性较小, 因此, 图 16 中的
SACA.jl 曲线在动态编译的 SACA C 基础上整体上移, 平均增幅约为 27.67 μs. 考虑到真实 Kernel 的计算时间都
在百万 μs 量级以上, 因此上述运行时开销对 Julia 程序整体执行时间的影响可以忽略不计.
100 SACA C (static link)
Kernel 执行时间 (μs) 70 SACA.jl
90
SACA C (dynamic link)
80
60
50
40
30
20
10
0
1 8 16 24 32 40 48 56 64
从核数量
图 16 Kernel 启动的运行时开销随从核数量的变化
为了评估使用 Julia 编写的 SACA Kernel 的原始性能, 我们将 Rodinia 基准测试集中的多个单线程 Julia 测试
课题移植到了 SACA.jl 上, 并使用 SACA 封装进行了初步的众核优化. 图 17 展示了使用 SACA.jl 实现的 Kernel
函数相较于 MPE 单线程版本的性能加速比. 对于拥有多个 Kernel 的测试课题, 其总执行时间为多个 Kernel 的平
均执行时间之和. 如图 17 所示, 所有基准测试课题经过 SACA.jl 优化后均获得了性能提升, 平均加速比为 31.46.
其中, streamcluster 课题获得了最高的 97.92 的超线性加速比, 这一方面是由于其 Kernel 函数的数据依赖关系简单、
可并行性较好, 另一方面得益于 CPE 的 LDCache 以及 LDM Stack 等优化机制的使用. backprop 和 lud 两道课题的
优化效果并不理想, 主要是由于其 Kernel 函数的实现复杂且计算密度较低, 特别是对于 backprop 课题, 如图 14 和
图 15 所示, 其 MPE 单线程版本在神威上的编译及垃圾回收的时间占比高达 64.42%, 因此难以充分发挥众核的计
算潜力.
基于 Julia 的元编程机制以及高层 API 封装, SACA.jl 在提升 Julia 程序性能同时并不会引入复杂的代码修改
工作. 图 18 展示了使用 SACA.jl 优化后的 Julia 基准测试课题的代码修改行数, 并使用不同颜色对修改的范围进
行了区分. 其中, “@saca”表示使用@saca 宏将 Kernel 函数加载至从核阵列运行, “Loop tiling”表示将 Kernel 函数
的核心计算部分映射到不同从核线程, “Runtime API”表示使用第 2.3.2 节介绍的 SACA 运行时 API, 例如通过
SACAShareLDMArray 申请从核阵列的 LDM 共享空间等, “Import SACA”表示对 SACA.jl 的引用. 如图 18 所示,
所有 Julia 测试课题的平均代码修改行数为 7, 特别地, streamcluster 课题在仅修改 3 行代码的情况下获得了 97.92
倍的性能提升. 仅从代码修改行数上分析, 使用 SACA.jl 与 CUDA.jl 在并行应用的开发难度上并没有较大差别. 然
而, 由于 SACA.jl 基于 SACA 编程模型设计, 并且进行了针对性的优化, 因此在国产众核平台上能够显著提升性
能, 实现更优的运行效果.
120 18 @saca
100 97.92 16 Loop tiling
14
80 12 Runtime API
加速比 60 57.89 代码修改行数 10 8 Import SACA
40 35.84 30.92 37.10 6
24.53 4
20 13.56 9.19
4.33 3.32 2
0 nn bfs nw lud 0 nn bfs nw lud
streamcluster backprop leukocyte pathfinder hotspot streamcluster backprop leukocyte hotspot particlefilter pathfinder
particlefilter
图 17 使用 SACA.jl 优化后的 Kernel 性能加速比 图 18 使用 SACA.jl 优化后的代码修改行数