
Page 124 - 《软件学报》2025年第12期
P. 124
吴月明 等: VulFewShot: 利用对比学习改进少样本漏洞分类 5505
2N
∑ 1
L SupCon = L i (11)
−1
N l i
i=1
综上所述, 总体客观损失 L All 的定义为公式 (12):
(12)
L All = ηL CE +(1−η)L SupCon
L CE 在公式 (9) 中定义, L SupCon 在公式 η 作为标量加权超参数, 以保持交叉熵损失和监
(11) 中定义, 我们使用
督对比损失的平衡.
4.1.4 漏洞类型分类
在训练阶段结束后, 可以获得经过训练的带有固定参数的深度学习分类模型, 对新的未标记的漏洞样本进行
分类. 具体来说, 给定一个新的漏洞样本, 首先进行静态分析, 以提取代码片段. 然后片段中的每一个单词都会被转
换成一个 768 维的向量, 并组合成漏洞样本的向量表示. 最后, 模型将向量表示作为输入, 输出相应的类型标签, 完
成漏洞分类任务.
4.2 模型超参数优化
由于本文使用与第 3 节相同的深度学习模型, 因此大多数超参数与第 3.2 节相同. 然后在对比学习中引入了
η ∈ {0.1,0.3,0.5,0.7,0.9} 进
两个新的超参数 τ 和 η. 对于使用对比学习框架的每个实验, 使用 τ ∈ {0.1,0.3,0.5,0.7} 和
行基于网格的超参数扫描. 最后, 根据当 τ = 0.1 和 η = 0.3 的情况在前 3 组实验中的平均表现, 选择 τ = 0.1 和 η = 0.3
作为最佳的超参数组合.
4.3 结 果
为了评估 VulFewShot 是否能有效解决对少样本类型分类差的问题, 我们研究了以下两个问题.
• RQ3: 与传统深度学习模型相比, 使用 VulFewShot 框架训练的模型在整体性能方面表现如何?
• RQ4: 在 MVD 和 MVD-part 数据集上, 与传统深度学习模型相比, 使用 VulFewShot 框架训练的模型在大、
中、小规模漏洞类型上的表现如何?
4.3.1 RQ3
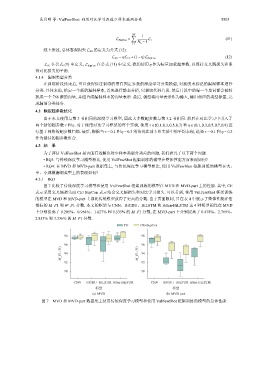
图 7 比较了传统深度学习模型和使用 VulFewShot 框架训练的模型在 MVD 和 MVD-part 上的性能. 其中, CE
表示采用交叉熵损失而 CE+SupCon 表示结合交叉熵损失和对比学习损失. 可以看到, 使用 VulFewShot 框架训练
的模型在 MVD 和 MVD-part 上都比传统模型获得了更高的分数. 由于页面限制, 只在表 4 中展示了整体性能评估
指标的 M_F1 和 W_F1 分数. 本文的框架与 CNN、BiGRU、BiLSTM 和 Atten-BiLSTM 这 4 种模型相比在 MVD
上分别提高了 0.205%、0.964%、1.627% 和 0.535% 的 M_F1 分数, 在 MVD-part 上分别提高了 0.478%、2.769%、
2.853% 和 3.336% 的 M_F1 分数.
CE CE+SupCon
98 98
96 96
M_F1 (%) 94 M_F1 (%) 94
92 92
90 90
CNN BiGRU BiLSTM Atten-BiLSTM CNN BiGRU BiLSTM Atten-BiLSTM
模型 模型
(a) MVD (b) MVD-part
图 7 MVD 和 MVD-part 数据集上使用传统深度学习模型和使用 VulFewShot 框架训练的模型的总体性能