
Page 121 - 《软件学报》2025年第12期
P. 121
5502 软件学报 2025 年第 36 卷第 12 期
如图 3 所示, 4 种模型在 MVD 上的表现都优于 MVD-part, 这证明传统的深度学习模型依赖于具有足够样本的
训练集, 因此在少样本漏洞类型的分类上表现不佳. CNN 的 diff 最小, 而 BiLSTM 的 diff 最大, 这进一步证实了我们
对模型的评估. BiLSTM 的最差表现符合我们的预期, 因为 BiGRU 和 Atten-BiLSTM 都是基于 BiLSTM 的改进模型.
综上所述, 对于漏洞分类任务, 4 种传统深度学习模型在 MVD 和 MVD-part 数据集上都取得了较好的性能,
但是他们在 MVD-part 的表现较差.
3.3.2 RQ2
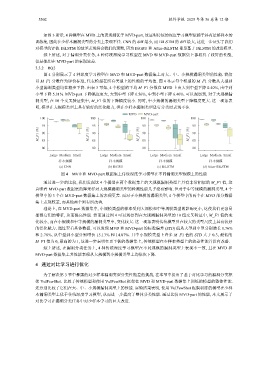
图 4 分别展示了 4 种深度学习模型在 MVD 和 MVD-part 数据集上对大、中、小规模漏洞类型的性能. 我们
以 M_F1 分数作为评价标准, 代表模型在所有类型上的性能的平均值. 图 4 显示每个模型的 M_F1 分数从大型到
小型漏洞类型均在稳步下降. 由表 3 可知, 4 个模型的平均 M_F1 分数在 MVD 上由大到中型下降 0.40%, 由中到
小型下降 5.31%. MVD-part 下降幅度更大, 大到中型下降 0.56%, 中到小型下降 6.40%. 可以观察到, 对于大规模漏
洞类型, 在 10 个交叉验证集中, M_F1 值的下降幅度较小. 同时, 中小规模的漏洞类型下降幅度更大. 这一现象表
明, 模型在大规模类型上具有较好的泛化能力, 但在少样本漏洞类型进行分类时表现不佳.
MVD MVD-part
100 100 100 100
95 95 95 95
M_F1 (%) 90 M_F1 (%) 90 M_F1 (%) 90 M_F1 (%) 90
85
85
85
85
80 80 80 80
Large Medium Small Large Medium Small Large Medium Small Large Medium Small
样本规模 样本规模 样本规模 样本规模
(a) CNN (b) BiGRU (c) BiLSTM (d) Atten-BiLSTM
图 4 MVD 和 MVD-part 数据集上传统深度学习模型在不同漏洞类型规模上的性能
通过进一步的比较, 我们发现这 4 个模型在两个数据集上的大规模漏洞类型上具有非常相似的 M_F1 值, 这
意味着 MVD-part 数据集的降采样对大规模漏洞类型的检测性能几乎没有影响. 但对于中等规模的漏洞类型, 4 个
模型中的 3 个在 MVD-part 数据集上的表现更差. 而对于小规模的漏洞类型, 4 个模型中的两个在 MVD 部分数据
集上表现较差, 而其他两个则有所改善.
理论上, 在 MVD-part 数据集中, 小规模类型的样本受到大规模和中等规模类型的影响更小, 这使我们更容易
捕捉它们的特征, 从而提高性能. 然而通过图 4 可以观察到在大规模漏洞类型的 10 组交叉验证中, M_F1 值的变
化较小, 而在小规模和中等规模的漏洞类型中, 变化较大. 这一现象表明传统模型只在较大的类型尺度上具有较好
的泛化能力. 通过查看具体数据, 可以发现 MVD 和 MVD-part 的标准偏差 (STD) 值从大型到中型分别增长 0.76%
和 2.78%, 从中型到小型分别增长 15.13% 和 14.07%. 且中小规模类型上许多 M_F1 值的 STD 大于 0.3, 最低的
M_F1 值为 0, 最高的为 1, 这进一步表明在更平衡的数据集上, 传统模型在少样本类型上的较差性能并没有改善.
综上所述, 在漏洞分类任务上, 4 种传统深度学习模型在不同规模的漏洞类型上表现不一致, 且在 MVD 和
MVD-part 数据集上其性能表现从大规模到小规模类型上均依次下降.
4 通过对比学习进行优化
为了解决第 3 节中暴露的对少样本漏洞类型分类性能差的挑战, 在本节中提出了基于对比学习的漏洞分类框
架 VulFewShot. 比较了传统模型和使用 VulFewShot 框架在 MVD 和 MVD-part 数据集上训练的模型的整体性能.
还分别比较了它们在大、中、小规模漏洞类型上的性能. 实验结果表明, 使用 VulFewShot 框架训练的模型在少样
本漏洞类型上优于传统深度学习模型, 从而进一步提高了整体分类性能. 通过比较 MVD-part 的性能, 本文展示了
对比学习在漏洞分类任务中对少样本学习的巨大改进.