
Page 120 - 《软件学报》2025年第12期
P. 120
吴月明 等: VulFewShot: 利用对比学习改进少样本漏洞分类 5501
组合在前 3 组实验中的平均表现选择了最佳的组合, 并将该超参数组合应用到了后续实验中. 表 1 展示了本文在
CNN 模型中所使用的参数.
表 2 则展示了本文在包括 BiGRU、BiLSTM 和 Atten-BiLSTM 等在内的 RNN 模型中所使用的参数. 使用
Adam 优化算法以及 0.000 02 的学习率训练所有的 4 种传统深度学习模型 [64] . 在模型训练好后, 不再修改这些模
型的参数, 并使用这些模型进行漏洞分类任务.
表 1 CNN 使用的参数 表 2 BiGRU, BiLSTM 和 Atten-BiLSTM 使用的参数
参数名 配置 参数名 配置
损失函数 交叉熵损失函数 损失函数 交叉熵损失函数
滤波器尺寸 (2, 3, 4) 激活函数 tanh
滤波器数量 256 层数 2
激活函数 ReLU 优化策略 Adam
池化层策略 最大池化 批量大小 32
优化策略 Adam 学习率 0.000 02
批量大小 32
学习率 0.000 02
3.3 结 果
为了评估传统深度学习模型在少样本漏洞类型上的分类性能, 本文研究了以下两个问题.
• RQ1: 传统深度学习模型在 MVD 和 MVD-part 数据集上的整体性能如何?
• RQ2: 4 种传统模型在 MVD 和 MVD-part 数据集上的大、中、小规模漏洞类型上的表现如何?
3.3.1 RQ1
4 种传统深度学习模型在 MVD 和 MVD-part 数据集上的实验结果总结如表 3 所示.
表 3 传统深度学习模型在 MVD 和 MVD-part 数据集上各性能指标表现
数据集 模型 M_FPR M_FNR M_F1 W_FPR W_FNR W_F1 Mean_L Mean_M Mean_S STD_L STD_M STD_S
CNN 0.015 3.020 97.582 0.113 0.494 99.493 99.182 98.982 94.797 1.466 2.330 16.824
BiGRU 0.018 4.046 96.694 0.090 0.638 99.348 99.006 99.463 92.904 1.476 2.138 17.153
MVD
BiLSTM 0.020 4.775 95.957 0.115 0.662 99.317 99.026 98.528 90.721 1.520 2.233 19.086
Atten-BiLSTM 0.014 2.824 97.621 0.066 0.503 99.487 99.169 98.797 95.092 1.338 2.137 16.281
CNN 0.054 2.959 96.818 0.104 2.058 97.910 97.920 98.594 94.145 2.291 4.161 17.402
BiGRU 0.119 6.751 92.579 0.191 4.557 95.410 96.090 94.412 87.616 3.619 7.120 23.217
MVD-part
BiLSTM 0.141 8.555 91.493 0.242 5.390 94.572 95.380 93.739 85.797 4.622 7.903 23.602
Atten-BiLSTM 0.117 5.786 93.960 0.201 4.460 95.537 95.925 96.329 89.936 4.186 6.656 17.895
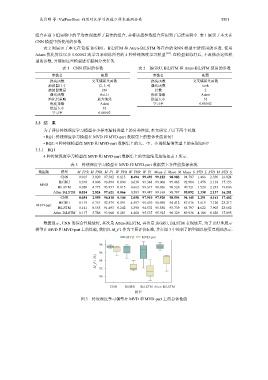
数据显示, CNN 的综合性能最好, 其次是 Atten-BiLSTM, 再次是 BiGRU, BiLSTM 表现最差. 为了更好地展示
模型在 MVD 和 MVD-part 上的性能, 我们以 M_F1 作为主要评价标准, 并在图 3 中绘制了箱型图以便更直观地表示.
MVD MVD-part
98
96
M_F1 (%) 94
92
90
CNN BiGRU BiLSTM Atten-BiLSTM
模型
图 3 传统深度学习模型在 MVD 和 MVD-part 上的总体性能