
Page 118 - 《软件学报》2025年第12期
P. 118
吴月明 等: VulFewShot: 利用对比学习改进少样本漏洞分类 5499
据集更加平衡, 更符合传统的少样本特征. 在构建该数据集时不能简单地将所有漏洞类型样本数量降采样到和原
始数据集中样本最少的漏洞类型数量一样, 因为这样新数据集将会丢失原始样本数量大小关系. 相反, 对于不同的
类型大小, 我们采用分层的降采样策略 [61,62] . 具体来说, 由于漏洞类型的第 1 个 1/3 区域的样本数量均在 400 以上,
第 2 个 1/3 区域的均在 80 以上, 因此将样本数量在 400 以上的漏洞类型视为大规模类型, 样本数量在 80–400 之
间的漏洞类型视为中等规模类型, 样本数量小于 80 的漏洞类型视为小规模类型. 基于这些定义, 我们将 40 种漏洞
类型相对平均地划分为大、中、小规模类型, 不同的规模类型分别包括 13、13、14 种不同的漏洞类型.
17 500
15 000
漏洞样本数量 10 000
12 500
7 500
5 000
2 500
0
漏洞类型
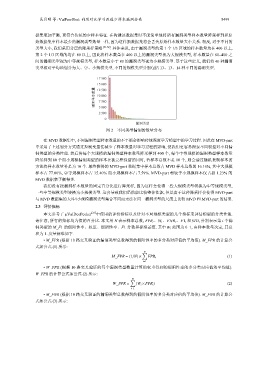
图 2 不同类型漏洞的数量分布
在 MVD 数据集中, 不同漏洞类型样本数量的不平衡会影响传统深度学习模型中的学习过程. 因此在 MVD-part
中采用了上述划分方式通过控制变量法减少了样本数量对学习过程的影响, 使我们更容易探索不同模型对不同漏
洞类型的分类性能. 然后将每个大规模的漏洞类型样本数量降采样到 400 个, 每个中等规模的漏洞类型样本数量
降采样到 80 个而小规模漏洞类型的样本在被完整保留的同时, 若样本总数不足 10 个, 则会通过随机复制样本的
方法将样本数量补足为 10 个. 最终获得的 MVD-part 数据集中样本总数占 MVD 样本总数的 16.16%, 其中大规模
样本占 77.00%, 中等规模样本占 15.40% 而小规模样本占 7.59%. MVD-part 相较于小规模样本仅占据 1.23% 的
MVD 数据集平衡得多.
我们没有按漏洞样本数量的固定百分比进行降采样, 因为这样会使得一些大规模类型转换为中等规模类型,
一些中等规模类型转换为小规模类型. 这会导致我们虽然能比较整体性能, 但是由于这种降采样会使得 MVD-part
与 MVD 数据集的大/中/小规模漏洞类型集合不同而无法在同一漏洞类型的尺度上比较 MVD 和 MVD-part 的结果.
2.3 评价指标
本文参考了 μVulDeePecker [23] 中使用的评价指标以及针对不同规模类型的几个指标来评估模型的分类性能.
请注意, 所有的指标均为值的百分比. 本文用 N 表示样本总数, FPR i 、 W i 、 FNR i 、 F1 i 和 STD i 分别表示第 i 个漏
洞类型的 M_F1 的假阳性率、权重、假阴性率、F1 分数和标准差值. 其中 W i 范围为 0–1, 由样本数量决定, 其总
和为 1. 度量标准如下.
• M_FPR (根据 10 路交叉验证的漏洞类型总数得到的假阳性率的多分类对应值的平均值). M_FPR 的计算公
式如公式 (1) 所示:
N ∑
M_FPR = (1/N)× FPR i (1)
i=1
• W_FPR (根据 10 路交叉验证的每个漏洞类型数量计算的权重得到的假阳性率的多分类对应值的平均值).
W_FPR 的计算公式如公式 (2) 所示:
N ∑
W_FPR = (W i ×FPR i ) (2)
i=1
• M_FNR (根据 10 路交叉验证的漏洞类型总数得到的假阴性率的多分类对应值的平均值). M_FNR 的计算公
式如公式 (3) 所示: