
Page 80 - 《软件学报》2025年第10期
P. 80
胡跃 等: 基于 FPGA 的格基数字签名算法硬件优化 4477
具有一定的成本优势. 文献 [30] 设计的核心运算模块具有更好的灵活性和可扩展性, 适合更加多元化且资源不敏
感的应用场景. 相比之下, 本文的设计方案在运算效率上具有明显的优势, 可以更好地满足高性能运算的应用场景.
4.3 综合性能对比分析
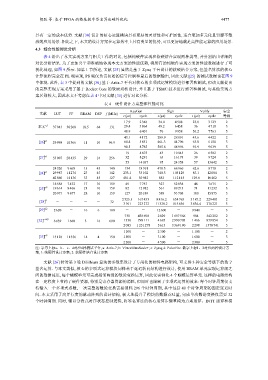
表 4 给出了本文实现方案与相关工作的对比, 包括纯硬件实现和软硬结合实现两种类型, 并分别给出详细的
对比分析结果. 为了更加公平和准确地体现本文方案的性能优势, 将所有的纯硬件实现方案的性能数据进行了可
视化处理, 如图 9 所示. 如第 1 节所述, 文献 [25] 虽然是基于 Zynq 平台设计的软硬结合方案, 但签名算法的核心
计算流程完全在 PL 端实现, PS 端仅负责初始的信号控制和最后的数据输出, 因此文献 [25] 的测试数据也在图 9
中体现. 此外, 表 3 中提到的文献 [30] 基于 Artix-7 平台对核心的多项式运算模块进行部署和测试, 但该文献提出
的完整实现方案采用了基于 Rocket Core 的软硬双核设计, 并且基于 TSMC 技术进行部署和测试, 与其他实现方
案区别较大, 因此本文不考虑在表 4 中对文献 [30] 进行对比分析.
表 4 硬件设计方案整体性能对比
KeyGen Sign Verify 安全
文献 LUT FF BRAM DSP f (MHz)
t (μs) cycle t (μs) cycle t (μs) cycle 等级
17.9 2 348 34.4 4 508 23.8 3 123 2
本文 a,1 37 943 30 268 18.5 64 131 29.4 3 864 49.2 6 458 36 4 718 3
48.9 6 401 76 9 958 56.2 7 763 5
43.1 4 172 289.9 28 091 45.6 4 422 2
[26] a,1 29 998 10 366 11 10 96.9 60.4 5 851 461.3 44 706 63.8 6 181 3
90.5 8 765 505.6 48 996 93.9 9 039 5
19 4 875 43 10 945 26 6 582 2
[27] b,1 53 907 28 435 29 16 256 32 8 291 63 16 178 39 9 724 3
55 14 037 95 24 358 57 13 642 5
24 320 9 668 15 45 140 134 18 761 478.3 66 966 62.6 8 770 2
a,1
[24] 29 987 11 274 23 45 142 233.1 33 102 740.3 105 129 85.1 12 084 3
42 860 14 136 33 45 127 401.4 50 982 883 112 145 129.6 16 462 5
18 558 7 432 17 10 159 49 7 757 327 52 038 48 7 675 2
[25] c,2 19 614 8 466 21 10 159 82 12 982 561 89 213 71 11 232 3
20 973 9 677 28 10 159 127 20 189 589 93 708 100 15 875 5
2 325.5 167 433 8 816.2 634 763 3 187.2 229 481 2
2
[28] - - - - 72
3 101 223 272 11 328.2 815 636 3 836.4 276 221 3
[29] d,2 2 620 - 16 6 100 - - 12 600 - 9 940 - 3
731 438 698 2 829 1 697 566 904 542 212 2
c+d,2
[32] 6 639 1 660 3 16 600 1 330 798 111 4 685 2 990 703 1 466 879 854 3
2 085 1 251 278 5 615 3 369 190 2 298 1 378 741 5
1 100 - 2 300 - 1 100 - 2
[33] c,2 13 128 11 556 14 4 150 1 500 - 3 100 - 1 600 - 3
2 200 - 4 500 - 2 300 - 5
注: 字母上标a、b、 c、d对应4种测试平台, a: Artix-7; b: VirtexUltraScale+; c: Zynq; d: PolarFire. 数字上标1、2对应两种设计方
案, 1: 纯硬件设计方案; 2: 软硬件结合设计方案
文献 [26] 针对第 3 轮 Dilithium 算法的参数集设计了专用化的硬件电路架构, 可支持 3 种安全等级下的数字
签名运算. 与本文类似, 核心的多项式运算模块同样基于延迟转向结构进行设计, 使用 BRAM 单元实现运算级之
间的数据延迟, 每个蝴蝶单元可完成相邻两级的数论变换运算, 因此仅实例化 4 个蝴蝶运算单元. 这样的电路结构
在一定程度上节约了硬件资源, 特别是寄存器资源的消耗, 但同时也限制了多项式运算的效率: 每个时钟周期仅支
持输入一个多项式系数, 一次完整的数论变换需要消耗 296 个时钟周期, 其中包括 40 个时钟周期的固定延迟时
间. 本文采用了高并行度的脉动阵列的设计架构, 极大地提升了模块的数据吞吐量, 完成单次数论变换仅需要 32
个时钟周期. 同时, 辅以分段式时序状态控制逻辑, 将签名算法的核心运算步骤重构为点乘运算、INTT 运算和模