
Page 334 - 《软件学报》2025年第10期
P. 334
张云婷 等: 中文对抗攻击下的 ChatGPT 鲁棒性评估 4731
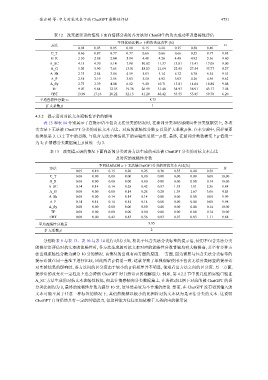
表 12 改变提示语的情况下面向情感分类时各方法对 ChatGPT 的攻击成功率及鲁棒性评估
不同扰动比例 α 下的攻击成功率 (%)
方法 rs
0.01 0.03 0.05 0.10 0.15 0.20 0.25 0.30 0.40
C_T 0.66 0.87 0.77 0.77 0.66 0.66 0.66 0.55 0.77 9.93
G_R 2.30 2.08 2.84 5.14 4.48 4.26 4.48 4.92 5.36 9.60
A_SC 4.15 4.70 5.14 7.98 10.82 11.37 13.01 15.41 17.05 9.00
A_G 5.03 5.90 7.65 13.01 18.03 21.64 22.95 27.54 33.77 8.27
A_Sh 2.73 2.84 3.06 4.59 5.03 5.14 6.12 6.78 6.34 9.53
A_P 2.51 2.19 2.95 3.83 3.50 4.92 5.03 4.26 4.59 9.62
A_Sy 2.73 3.39 4.04 6.12 9.40 10.71 13.01 14.64 18.80 9.08
TF 9.07 9.84 12.35 19.78 26.99 31.48 34.97 38.91 43.17 7.48
CBT 13.99 17.16 20.22 32.13 41.20 48.42 53.55 55.85 59.78 6.20
平均鲁棒性分数 rs 8.75
β 1
扩大系数
4.3.2 提示语对对抗文本流畅性评估的影响
表 13 和表 14 分别展示了在提示语不包含无法分类的情况时, 在新闻分类和情感倾向性分类数据集上, 各攻
击方法下无法被 ChatGPT 分类的对抗文本占比、对应的流畅性分数 fs 以及扩大系数 β 值. 在本实验中, 同样需要
按类似第 3.1.3.2 节中的思路, 与包含无法分类情况下的实验结果统一 β 值. 最终, 在新闻分类数据集上 β 值统一
为 2; 在情感分类数据集上 β 值统一为 3.
表 13 改变提示语的情况下面向新闻分类时各方法生成的无法被 ChatGPT 分类的对抗文本占比
及对应的流畅性分数
不同扰动比例 α 下无法被ChatGPT分类的对抗文本占比(%)
方法 fs
0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.50
C_T 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10.00
G_R 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.14 10.00
A_SC 0.14 0.14 0.14 0.28 0.42 0.97 1.53 1.11 2.36 9.84
A_G 0.00 0.00 0.00 0.14 0.28 0.28 1.39 1.67 3.06 9.85
A_Sh 0.00 0.00 0.14 0.14 0.14 0.00 0.00 0.00 0.00 9.99
A_P 0.14 0.14 0.14 0.14 0.14 0.00 0.00 0.00 0.00 9.98
A_Sy 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.14 10.00
TF 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.14 10.00
CBT 0.00 0.00 0.42 0.83 0.56 0.83 0.97 0.83 1.11 9.88
平均流畅性分数 fs 9.95
扩大系数 β 2
分别将表 9 与表 13、表 10 与表 14 进行对比可知, 相比于包含无法分类标签的提示语, 使用不包含无法分类
的提示语评估对抗文本的流畅性时, 各方法生成的对抗文本对应的流畅性分数普遍均有大幅提高, 甚至有多种方
法出现流畅性分数为满分 10 分的情况. 该情况的出现有两方面的原因. 一方面, 因为需要与包含无法分类标签的
β 值需一致. 这就导致了单独观察使用不包含无法分类标签的提示语
提示语放在同一基准下进行比较, 因此两者
对实验结果的影响时, 各方法间的区分度由于较小的 β 值相差并不明显, 很难看出方法之间的区分度. 另一方面,
提示语的改变在一定程度上也会降低 ChatGPT 对自然语言的理解能力. 例如, 第 4.2.2 节中的几组的实验已验证
A_SC 方法生成的对抗文本流畅性较低, 但其在情感倾向分类数据集上, 在各扰动比例下对应的被 ChatGPT 的误
分类比例均为 0, 最终的流畅性分数为满分 10 分, 这显然是较为不合理的结论. 然而, 在 ChatGPT 没有得到输入的
文本可能不属于任意一种标签的情况下, 其仍然能够以极小的比例将对抗文本认为是无法分类的文本. 这说明
ChatGPT 自身仍然具有一定的纠错能力, 但这种能力往往更加依赖于人类给出的提示词.