
Page 331 - 《软件学报》2025年第10期
P. 331
4728 软件学报 2025 年第 36 卷第 10 期
的流畅性分数均保持在中等水平, 且这些方法的攻击成功率也远高于字符级的方法. 因此这些方法是 ChatGPT、
中文 BERT 等目标模型在设计防御方法时需要重点考虑的攻击方法.
表 10 面向情感分类时各方法生成的无法被 ChatGPT 分类的对抗文本占比及对应的流畅性分数
不同扰动比例 α 下无法被ChatGPT分类的对抗文本占比 (%)
方法 fs
0.01 0.03 0.05 0.10 0.15 0.20 0.25 0.30 0.40
C_T 1.39 1.04 1.39 1.62 1.73 2.89 2.31 2.42 2.31 9.43
G_R 3.35 3.46 3.58 5.20 7.39 9.01 10.62 11.89 13.39 7.74
A_SC 8.20 7.04 9.24 14.43 19.28 25.75 29.10 32.45 34.99 3.98
A_G 8.20 8.43 9.12 15.24 24.60 32.56 40.88 51.27 64.09 1.52
A_Sh 3.70 4.16 3.93 6.24 7.51 9.58 9.93 12.47 14.78 7.59
A_P 3.35 4.73 4.04 4.73 5.89 5.66 6.47 6.81 6.81 8.38
A_Sy 3.23 2.66 3.93 5.20 9.01 12.01 14.78 18.59 23.33 6.91
TF 8.43 8.55 10.05 11.66 15.70 17.21 19.05 24.13 29.91 5.18
CBT 10.39 11.66 13.05 17.32 20.09 23.90 26.21 27.83 31.64 3.93
平均流畅性分数 fs 6.07
扩大系数 β 3
4.2.2.2 文本相似性评估结果
为了进一步验证所提的 OFS 方法的有效性, 本文使用了 4 种文本相似度计算方法对原文本与对抗文本之
间的相似度进行全面评估. 虽然文本相似性与流畅性是两个截然不同的概念, 但文本相似性在一定程度上能
够反映出对抗文本的流畅性. 若原文本与对抗文本之间的相似度很低, 则说明对抗文本在原文本的基础上进
行了较大的扰动, 这些改动有较大的概率影响其原始语义以及词法和语法的正确性, 从而对其流畅性有较大
的影响. 因此, 本文通过评估原文本与对抗文本之间的相似性, 来对各方法生成的对抗文本的流畅性进行进一
步验证.
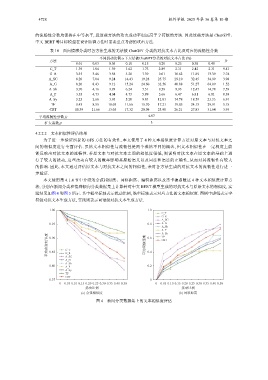
本文使用第 4.1.4 节中介绍的余弦相似度、词移距离、编辑距离以及杰卡德系数这 4 种文本相似度计算方
法, 分别在新闻分类和情感倾向分类数据集上计算针对中文 BERT 模型生成的对抗文本与原始文本的相似度, 实
验结果如图 4 和图 5 所示. 其中横坐标轴表示扰动比例, 纵坐标轴表示对应方法的文本相似度. 图例中虚线表示字
符级对抗文本生成方法, 实线则表示词语级对抗文本生成方法.
1.00 1.0
C_T
G_R
A_SC
0.95 0.8 A_G
A_Sh
A_P
A_Sy
平均余弦相似度 0.90 C_T 平均词移距离 0.6 CBT
TF
0.85
0.4
G_R
A_SC
A_G
A_Sh
0.80 A_P 0.2
A_Sy
TF
CBT
0.75 0
0 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.50 0 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.50
扰动比例 扰动比例
(a) 余弦相似度 (b) 词移距离
图 4 新闻分类数据集上的文本相似度评估