
Page 330 - 《软件学报》2025年第10期
P. 330
张云婷 等: 中文对抗攻击下的 ChatGPT 鲁棒性评估 4727
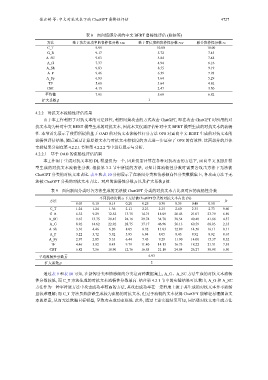
表 8 面向情感分类的中文 BERT 鲁棒性评估 (软标签)
方法 基于攻击成功率的鲁棒性分数 rsu 基于置信度的鲁棒性分数 rsv 联合鲁棒性分数 rs
C_T 9.99 10.00 10.00
G_R 9.17 5.72 7.45
A_SC 9.03 5.84 7.44
A_G 7.37 4.94 6.16
A_Sh 9.83 8.55 9.19
A_P 9.46 6.39 7.93
A_Sy 6.93 3.64 5.29
TF 5.60 3.64 4.62
CBT 4.13 2.47 3.30
平均值 7.95 5.69 6.82
扩大系数 β 1
4.2.2 对抗文本流畅性评估结果
由于本工作利用了对抗文本的可迁移性, 利用间接攻击的方式攻击 ChatGPT, 即在攻击 ChatGPT 时所用的对
抗文本均为针对中文 BERT 模型生成的对抗文本, 因此本文仅需评估针对中文 BERT 模型生成的对抗文本的流畅
性. 本节首先展示了使用所提的基于 OAD 的对抗文本流畅性打分方法 OFS 对面向中文 BERT 生成的对抗文本的
流畅性评估结果, 随后通过计算原始文本与对抗文本相似度的方式进一步证实了 OFS 的有效性. 这两部分的具体
实验结果分别在第 4.2.2.1 节和第 4.2.2.2 节中进行展示与分析.
4.2.2.1 基于 OAD 的流畅性评估结果
本工作用于生成对抗文本的 DL 模型仅为一个, 因此仅需计算在各种对抗攻击的方法下, 面向中文 BERT 模
型生成的对抗文本流畅性分数. 根据第 3.2 节中所提的方法, 可知计算流畅性分数时需要各攻击方法下无法被
ChatGPT 分类的对抗文本占比. 表 9 和表 10 分别展示了在新闻分类和情感倾向性分类数据集上, 各攻击方法下无
法被 ChatGPT 分类的对抗文本占比、对应的流畅性分数 fs 以及扩大系数 β 值.
表 9 面向新闻分类时各方法生成的无法被 ChatGPT 分类的对抗文本占比及对应的流畅性分数
不同扰动比例 α 下无法被ChatGPT分类的对抗文本占比 (%)
方法 fs
0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.50
C_T 1.24 1.24 1.36 2.11 2.23 2.35 2.60 2.35 2.73 9.60
G_R 6.32 9.29 12.52 13.75 14.75 18.09 20.45 21.07 23.79 6.89
A_SC 9.67 13.75 20.45 24.16 29.74 34.70 38.54 40.40 41.88 4.37
A_G 8.92 14.62 22.92 28.75 37.17 46.96 56.13 60.59 68.03 2.35
A_Sh 3.10 4.46 6.20 8.05 8.92 11.03 12.89 14.50 16.11 8.11
A_P 3.22 3.72 5.82 5.95 6.94 8.05 8.43 8.92 8.92 8.67
A_Sy 2.97 2.85 5.33 6.44 7.43 9.29 11.90 14.00 15.37 8.32
TF 4.46 5.82 8.43 9.79 11.40 14.13 16.73 18.22 21.31 7.55
CBT 6.82 7.56 10.90 12.76 16.85 21.19 24.04 26.27 30.98 6.50
平均流畅性分数 fs 6.93
β 2
扩大系数
通过表 9 和表 10 可知, 在新闻分类和情感倾向分类这两种数据集上, A_G、A_SC 方法生成的对抗文本流畅
性分数较低, 而 C_T 方法生成的对抗文本流畅性分数最高. 结合第 4.2.1 节中的实验结果可以看出, A_G 和 A_SC
方法作为一种字符级方法中攻击成功率较高的方法, 其攻击成功率在一定程度上源于其生成的对抗文本并不流畅
且较难理解; 而 C_T 方法虽然能够生成较为流畅的对抗文本, 但过于流畅的文本使得 ChatGPT 能够轻易理解该文
本的原意, 从而无法欺骗目标模型, 导致攻击成功率很低. 此外, 通过上述实验结果可知, 词语级对抗文本生成方法