
Page 243 - 《软件学报》2025年第10期
P. 243
4640 软件学报 2025 年第 36 卷第 10 期
点注意力机制 (Node-Att)、引入边注意力机制 (Edge-Att), 以及引入 Transformer 的多头注意力机制 (本模型) 的实
验结果. 其中, 节点注意力机制通过计算当前节点与其邻居节点之间的注意力权重, 并根据这些权重来聚合邻居节
点的信息. 边注意力机制不仅考虑节点之间的关系, 还考虑了图中的边, 通过关联边的权重来调节节点之间的信息
传递. 而本文所使用的 Transformer 多头注意力机制可以在序列中建立全局依赖关系, 以便更好地捕捉序列中的长
距离依赖. 同时, 通过引入多个注意力头, 每个注意力头都会学习不同的注意力权重, 从而允许模型同时关注序列
中不同位置的不同特征.
1.0
Accuracy Precision Recall F1-score
0.89
0.85 0.870.870.87
0.83
0.81 0.81 0.82
0.8 0.79
0.74 0.76 0.73
0.68 0.7
0.63
0.6
数值
0.4
0.2
0
None-Att Node-Att Edge-Att 本模型
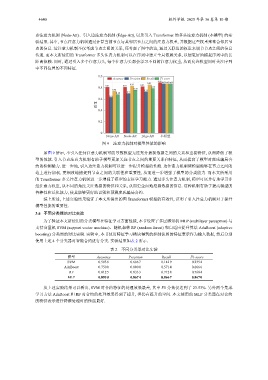
图 9 注意力机制对模型性能的影响
如图 9 所示, 不引入任何注意力机制可能导致模型无法充分捕捉数据之间的关系和重要特征, 从而降低了模
型的性能. 引入节点注意力机制有助于模型更加关注节点之间的重要关系和特征, 从而提高了模型对庞氏骗局合
约的检测能力. 进一步地, 引入边注意力机制可以进一步提升模型的性能. 边注意力机制使模型能够在节点之间的
边上进行加权, 更细致地捕捉到节点之间的关联性和重要性, 从而进一步增强了模型的分类能力. 而本文所采用
的 Transformer 多头注意力机制进一步增强了模型的表征学习能力. 通过多头注意力机制, 模型可以并行地学习多
组注意力权重, 从不同的角度关注数据的特征和关系, 从而更全面地挖掘数据的信息. 这种机制有助于提高模型的
鲁棒性和泛化能力, 使其能够更好地识别和预测庞氏骗局合约.
综上所述, 上述实验结果验证了本文所提出的图 Transformer 模型的有效性, 证明了引入注意力机制对于提升
模型性能的重要性.
3.6 不同分类器的对比实验
为了验证本文所使用的分类模型在特征学习方面性能, 本节设置了多层感知机 MLP (multilayer perceptron) 与
支持向量机 SVM (support vector machine)、随机森林 RF (random forest) 和自适应提升算法 AdaBoost (adaptive
boosting) 分类器的对比实验. 实验中, 本节使用特征学习模块得到的控制流图的特征表示作为输入数据, 然后分别
使用上述 4 个分类器对智能合约进行分类. 实验结果如表 2 所示.
表 2 不同分类器对比实验
模型 Accuracy Precision Recall F1-score
SVM 0.593 8 0.666 7 0.142 9 0.235 4
AdaBoost 0.750 0 0.800 0 0.571 4 0.666 6
RF 0.812 5 0.833 3 0.712 8 0.768 4
MLP 0.893 0 0.867 4 0.866 7 0.867 0
从上述实验结果可以看出, SVM 对合约特征的处理效果最差, 其中 F1 分数仅达到了 23.53%. 另外两个集成
学习方法 AdaBoost 和 RF 对合约的处理效果得到了提升, 但仍有提升的空间. 本文使用的 MLP 分类器在对合约
的特征表示进行降维处理时的性能最好.