
Page 410 - 《软件学报》2025年第9期
P. 410
何玉林 等: 基于时空注意力的多粒度链路预测算法 4321
NC-LGBM 比 PR-CN 预测性能有所提升, 但由于输入的多种相似性指数特征难以表示社交网络的复杂特征而使
得其预测能力受限. 与这类方法不同, 本文没有构建具体的网络相似性指数, 而是通过建立深度学习模型来建模社
交网络的时空特征, 从社交网络数据中自适应地提取出深层的抽象特征.
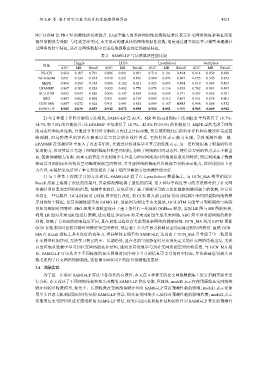
表 2 SAMG-LP 与基准算法性能比较
Haggle LH10 LyonSchool workplace
算法
AUC MR Recall AUC MR Recall AUC MR Recall AUC MR Recall
PR-CN 0.864 0.107 0.791 0.806 0.091 0.691 0.714 0.101 0.494 0.814 0.059 0.680
NC-LGBM 0.851 0.124 0.814 0.810 0.261 0.876 0.884 0.095 0.807 0.655 0.545 0.853
MljFE 0.804 0.283 0.734 0.896 0.112 0.821 0.923 0.083 0.894 0.619 0.903 0.897
LPANMF 0.867 0.105 0.824 0.853 0.092 0.770 0.878 0.136 0.838 0.702 0.091 0.495
GC-LSTM 0.902 0.043 0.826 0.896 0.107 0.824 0.862 0.099 0.771 0.827 0.062 0.701
SRG 0.887 0.062 0.802 0.831 0.083 0.719 0.893 0.315 0.867 0.931 0.078 0.901
GCN_MA 0.887 0.072 0.824 0.911 0.091 0.854 0.889 0.167 0.933 0.908 0.088 0.872
SAMG-LP 0.915 0.039 0.853 0.942 0.072 0.898 0.924 0.081 0.900 0.965 0.049 0.942
2) 与 2 种基于矩阵分解的方法相比, SAMG-LP 在 AUC、MR 和 Recall 指标上比 MljFE 平均取得了 18.7%、
54.7% 和 7.8% 的性能提升; 比 LPANMF 平均取得了 14.7%、42.8% 和 29.5% 的性能提升. MljFE 虽然考虑了网络
的动态性和拓扑结构, 并通过非负矩阵分解的方式建立目标函数, 然后使用优化后的特征矩阵和参数矩阵完成链
路预测, 但这种简单的矩阵分解难以学习复杂的非线性关系, 它的特征表示能力有限, 导致预测性能一般.
LPANMF 在邻接矩阵中加入了攻击者矩阵, 并通过对抗训练学习节点的低维表示, 这一定程度提高了模型的特征
提取能力, 但该算法只考虑了网络的稀疏性和空间结构, 忽略了网络的时间动态性, 使得学习到的节点表示不够全
面, 链路预测能力有限. 而本文的算法首先利用多头注意力神经网络从时间维度提取时间特征, 然后利用基于数据
驱动学习到的拓扑结构从空间维度提取空间特征, 并考虑网络的稀疏性以提高节点的表示能力, 在理论层面上更
为合理, 实验结果也证明了本文算法相比于基于矩阵分解的方法预测性能更好.
3) 与 3 种基于深度学习的方法相比, SAMG-LP 除了在 LyonSchool 数据集上, 与 GCN_MA 模型相比在
Recall 指标上取得了次优的结果外, 其余情况都取得了最优的结果. 这 3 种基于深度学习的方法都考虑了社交网
络的时间信息和空间结构信息, 预测性能较好, 这也证明了基于深度学习的方法在链路预测问题上的优势, 但它们
也存在一些局限性. GC-LSTM 对 LSTM 模型进行改进, 将 GCN 嵌入到 LSTM 的内部结构中来同时提取网络快照
序列的时空特征, 但其预测性能不如 SAMG-LP, 这是因为相比于本文算法, GC-LSTM 只能学习到短期的空间特
征和局部的时间特征. SRG 深度生成模型设计了基于条件归一化流的 DGFlow 模块, 实现 LR 图与 HR 图的转换,
利用 LR 图对未来 HR 图进行预测, 进而通过 DGFlow 将未来 HR 图生成未来网络. SRG 简单地考虑网络的拓扑
结构, 忽略了节点间的影响程度不同, 且在训练过程没有考虑到复杂网络的稀疏特性. GCN_MA 利用 LSTM 更新
GCN 参数来同时建模局部时间特征和空间特征, 然后基于多头注意力机制从全局角度建模时间特征. 虽然 GCN_
MA 在 Recall 指标上具有良好的竞争力, 但其整体表现不如 SAMG-LP, 这是由于 GCN_MA 只考虑了单一粒度的
社交网络时间序列, 无法学习到它的中、长期趋势, 且在考虑空间特征时只从预先定义的社交网络结构出发, 无法
自适应地从数据中学习到社交网络的拓扑结构, 进而更有效地学习到社交网络的空间结构信息. 与 GCN_MA 相
比, SAMG-LP 可以从多个不同粒度的社交网络时间序列中学习到信息更丰富的时空特征, 并从稀疏惩罚损失函
数考虑到了社交网络的稀疏性, 这使得 SAMG-LP 的综合预测性能更好.
3.4 消融实验
为了进一步验证 SAMG-LP 算法中各组件的有效性, 本文在 4 种真实的社交网络数据集上进行消融实验并进
行分析. 本文设计了不同网络结构和损失函数的 SAMG-LP 算法变体, 具体地, model0 表示仅使用原始社交网络快
照序列的单粒度模型, 探究中、长期粒度社交网络快照序列对 SAMG-LP 算法预测性能的影响; model1 表示仅使
用单头注意力机制提取时间特征的 SAMG-LP 算法, 探究社交网络多元演化对预测性能的影响程度; model2 表示
仅使用历史邻居矩阵进行图卷积的 SAMG-LP 算法, 探究自适应提取拓扑结构的组件对 SAMG-LP 算法的预测性