
Page 395 - 《软件学报》2025年第9期
P. 395
4306 软件学报 2025 年第 36 卷第 9 期
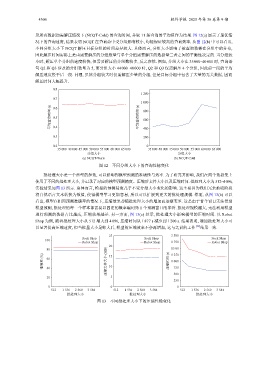
及所有数据均需解压情况下 (NCQT-Cold) 的查询时间, 并取 11 条查询的平均值作为结果. 图 12(a) 展示了最优情
况下的查询速度, 结果表明 NCQT 在查询命中受分组影响较小, 均能保证较高的查询效率. 从图 12(b) 中可以看出,
不同分组大小下 NCQT 解压目标分组的时间差异较大. 具体而言, 分组大小影响了被查询数据在分组中的分布,
因此解压时间实际上是由需要解压的分组数量与单个分组需要解压的数据量二者之间的平衡性决定的. 当分组较
小时, 解压单个分组的速度较快, 但需要解压的分组数较多, 反之亦然. 例如, 分组大小在 35 000–40 000 时, 查询语
句 Q2 和 Q3 涉及的分组数量为 5, 而分组大小 44 000–48 000 时, Q2 和 Q3 仅需解压 4 个分组, 因此前一段的平均
解压速度慢于后一段. 同理, 虽然分组较大时仅需解压少量的分组, 但是目标分组中包含了大量的无关数据, 因而
解压时间大幅提升.
0.8
1 200
0.7
1 000
平均查询时间 (s) 0.5 平均查询时间 (s) 800
0.6
600
0.4
0.3 400
200
0.2 0
35 000 40 000 45 000 50 000 55 000 60 000 65 000 35 000 40 000 45 000 50 000 55 000 60 000 65 000
分组大小 分组大小
(a) NCQT-Warm (b) NCQT-Cold
图 12 不同分组大小下的查询性能变化
批处理大小是一个典型的参数, 可以影响到模型预测的准确性与效率. 为了研究其影响, 我们在两个数据集上
使用了不同的批处理大小, 并记录了对应的模型预测精度、压缩后文件大小以及压缩时间. 批处理大小为 512–4 096,
实验结果如图 13 所示. 总体而言, 模型的预测精度几乎不受分批大小变化的影响. 这主要因为我们冗余抽取阶段
将自然语言文本转换为数值, 使得模型学习更加容易, 所以可以扩展到更大的批处理规模. 然而, 从图 13(b) 可以
看出, 模型在相同预测准确率的情况下, 压缩效果却随批处理大小的增加而逐渐变差. 这是由于首个窗口无法借助
模型预测, 批处理的每一个样本都需要以固定的概率编码第 1 个预测窗口的字符. 批处理规模越大, 无法利用模型
进行预测的数据占比越高, 压缩效果越差. 另一方面, 图 13(c) 显示, 批处理大小影响模型的压缩时间. 以 Robot
Shop 为例, 随着批处理大小从 512 增大到 4 096, 压缩时间从 1 877 s 减少到 1 200 s. 结果表明, 增加批处理大小可
以显著提高压缩速度, 但当批量大小足够大后, 模型的压缩效率不会再增加, 这与之前的工作 [52] 结果一致.
25 2 500
Sock Shop Sock Shop Sock Shop
100
Robot Shop Robot Shop 1 750 Robot Shop
80 15 00
1 250
准确率 (%) 60 压缩文件大小 (MB) 20 压缩时间 (s) 1 000
15
10
750
40
20 5 500
250
0 0 0
512 1 536 2 560 3 584 512 1 536 2 560 3 584 512 1 536 2 560 3 584
批处理大小 批处理大小 批处理大小
图 13 不同批处理大小下的压缩性能变化