
Page 390 - 《软件学报》2025年第9期
P. 390
王尚 等: 基于神经网络的分布式追踪数据压缩和查询方法 4301
Ticket 数据集为例, TRACE 和 DZip 的压缩比是 gzip 的 1.98 倍和 2.02 倍, 对于效果最好的传统压缩算法 lzma,
TRACE 和 DZip 也有 4%–6% 的效果提升. 这证明了基于神经网络的压缩算法相较于传统压缩算法有更高的压缩
上限, 这是因为传统压缩算法虽然可以识别数据中的局部冗余, 但其缺乏对数据集整体数据分布的理解, 而神经网
络压缩算法可以更好地学习数据集中的整体信息, 从而实现更高效的压缩.
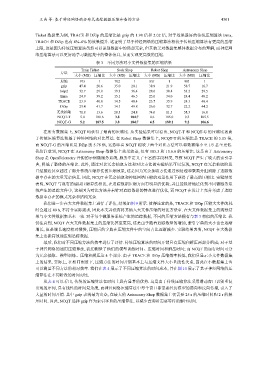
表 3 不同方法对小文件数据集的压缩结果
Train Ticket Sock Shop Robot Shop Astronomy Shop
方法
大小 (MB) 压缩比 大小 (MB) 压缩比 大小 (MB) 压缩比 大小 (MB) 压缩比
原始 975 1 702 1 851 1 981 1
gzip 47.4 20.6 35.0 20.1 38.9 21.9 58.7 16.7
bzip2 32.7 29.8 19.3 36.4 28.0 30.4 33.2 29.5
lzma 24.9 39.2 15.1 46.5 25.0 34.0 24.4 40.2
TRACE 23.9 40.8 14.5 48.4 23.7 35.9 24.3 40.4
DZip 23.4 41.7 14.1 49.8 26.0 32.7 22.2 44.2
冗余抽取 71.8 13.6 28.3 24.8 74.0 11.5 58.3 16.8
NCQT-T 5.4 180.6 3.8 184.7 4.6 185.0 9.3 105.5
NCQT-G 5.2 187.5 3.8 184.7 4.5 189.1 9.2 106.6
在所有数据集上, NCQT 均获得了最高的压缩比. 从实验结果可以看出, NCQT-T 和 NCQT-G 的压缩比远高
于传统压缩算法和基于神经网络的对比算法. 在 Robot Shop 数据集上, NCQT-T 的压缩比是 TRACE 的 5.15 倍,
而 NCQT-G 的压缩比是 DZip 的 5.78 倍, 这意味着 NCQT 相较于两个对比方法可以将数据缩小至 1/5 甚至更低.
我们注意到, NCQT 在 Astronomy Shop 数据集上效果较差, 仅有 105.5 和 10.6.6 的压缩比. 这是由于 Astronomy
Shop 是 OpenTelemetry 开源的示例微服务系统, 服务中定义了丰富的字段种类, 导致 NCQT 产生了较大的索引字
典, 降低了整体的压缩比. 此外, 通过对比冗余抽取方法和对比方法的实验结果可以发现, NCQT 在冗余抽取阶段
已经接近甚至超过了部分传统压缩算法的压缩效果, 这是因为冗余抽取方法通过预处理和聚类分组消除了追踪数
据中存在的大量冗余信息. 因此, NCQT 在冗余抽取和神经网络压缩的双重作用下获得了最高的压缩比. 实验结果
表明, NCQT 与现有的通用压缩算法相比, 在追踪数据压缩方面有明显的优势, 并且能很好地泛化到不同微服务系
统产生的追踪文件中, 这是因为对比方法并未针对追踪数据的特点进行优化, 而 NCQT 在设计上充分考虑了追踪
数据中存在的模式冗余和结构冗余.
我们进一步在大文件数据集上进行了评估, 结果如图 9 所示. 值得注意的是, TRACE 和 DZip 压缩大文件的耗
时会超过 80 h, 不符合实际需求, 因此本文并没有将其纳入大文件压缩的对比方法中. 在大文件数据集上的观察结
果与小文件数据集基本一致. 对于每个微服务系统产生的追踪数据, 不同的压缩方法拥有与表 3 相似的压缩比. 我
们注意到, NCQT 在大文件数据集上的压缩比甚至更高, 这是由于随着追踪数量的增加, 索引字典的大小也会逐渐
增长, 但是增长速度相对缓慢, 压缩后的字典在压缩文件中的空间占比逐渐减少. 实验结果表明, NCQT 在大数据
集上也能高效地压缩追踪数据.
最后, 我们对不同压缩方法的效率进行了评估. 传统压缩算法的时间开销只有压缩和解压两部分组成; 对于基
于神经网络的通用压缩算法, 我们测量了他们的模型训练时间、压缩时间和解压时间; 而 NCQT 的运行时间可分
为冗余抽取、模型训练、压缩和解压这 4 个部分. 由于 TRACE 和 DZip 压缩效率较低, 我们只显示小文件数据集
上的结果. 实际上, 在相同配置下, 压缩方法的时间开销基本上与压缩文件大小呈线性关系, 因此在小数据集上也
可以测量不同方法的相对效率. 我们在表 4 展示了不同压缩算法的时间成本, 并在图 10 展示了基于神经网络的压
缩算法在不同阶段的时间对比.
从表 4 可以看出, 传统的压缩算法在时间上具有显著的优势. 这是由于传统压缩算法采用滑动窗口识别重复
出现的序列, 具有线性的时间复杂度, 而神经网络压缩算法中每个窗口都需要经历模型的前向和反向传播, 引入了
大量的时间开销. 其中 gzip 表现最为出众, 在最大的 Astronomy Shop 数据集上仅需要 25 s 的压缩时间和 2 s 的解
压时间. 因此, NCQT 选择 gzip 作为索引字典的压缩算法, 以减少查询时需要等待的解压时间.