
Page 289 - 《软件学报》2025年第9期
P. 289
4200 软件学报 2025 年第 36 卷第 9 期
缘信息, 因而学生网络训练时难以获得足够的知识.
表 6 不同温度 τ ( ) 下 MaskET 的实验结果 (%)
方法 P R F1
baseline 87.1 71.8 78.7
τ=0.5 82.8 76.2 79.4
τ=1 84.3 75.8 79.8
τ=1.5 83.0 76.8 79.7
τ=2 87.7 71.7 78.9
τ=10 85.5 72.2 78.3
τ=20 89.2 69.4 78.0
τ=30 88.7 69.0 77.6
τ=50 89.5 68.4 77.5
1.0
分
割 0.8
图
0.6
信 0.4
息
熵 0.2
图
0
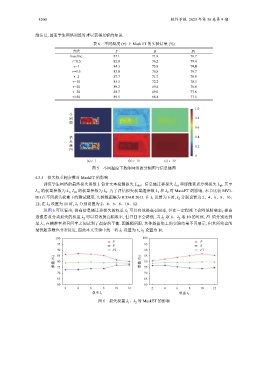
(a) τ=1 (b) τ=10 (c) τ=30
图 5 不同温度下教师网络的分割图与信息熵图
4.3.5 损失权重超参数对 MaskET 的影响
训练学生网络的最终损失函数 L 包含文本检测损失 L det 、信息熵迁移损失 L e 和逐像素点分类损失 L pi , 其中
t
L e 的权重参数为 λ 1 , L p 的权重参数为 λ 2 . 为了评估损失权重超参数 λ 1 和 λ 2 对 MaskET 的影响, 本节比较 MV3-
t
i
DB 在不同损失权重下的测试精度, 实验数据集为 ICDAR 2015. 在 λ 1 设置为 6 时, λ 2 分别设置为 2、4、6、8、10、
12; 在 λ 2 设置为 10 时, λ 1 分别设置为 2、4、6、8、10、12.
从图 6 可以看出, 提高信息熵迁移损失的权重 λ 1 可以有效提高召回率, 但在一定程度上会降低精确率; 提高
逐像素点分类损失的权重 λ 2 可以有效提高精准率, 但召回率会降低. 当 λ 1 取 6、λ 2 取 10 的时候, F1 值分别达到
最大, 在精准率和召回率之间达到了最好的平衡. 因篇幅所限, 其他数据集上的实验结果不再展示, 但其所给出的
最优超参数也非常接近, 因此本文实验中统一将 λ 1 设置为 6, λ 2 设置为 10.
100 100
P P
95 95
R R
90 F1 90 F1
数值 (%) 85 数值 (%) 85
80
80
75
75
70 70
65 65
60 60
2 4 6 8 10 12 2 4 6 8 10 12
权重 λ 1 权重 λ 2
图 6 损失权重 λ 1 、λ 2 对 MaskET 的影响