
Page 155 - 《软件学报》2025年第9期
P. 155
4066 软件学报 2025 年第 36 卷第 9 期
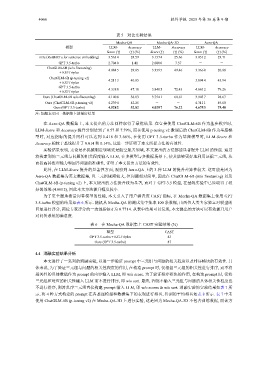
表 5 对比实验结果
Mecha-QA Mecha-QA-3D Aero-QA
模型 LLM- Accuracy LLM- Accuracy LLM- Accuracy
Score (↑) (↑) (%) Score (↑) (↑) (%) Score (↑) (↑) (%)
m3e (RoBERTa for sentence embedding) 3.563 4 28.59 3.157 4 25.66 3.051 2 23.71
GPT 3.5-turbo 2.704 0 1.41 2.000 0 7.57 - -
ChatGLM-6B (w/o finetuning) 4.084 5 29.85 3.359 5 49.46 3.366 0 20.88
+ KG-Triples
ChatGLM-6B (p-tuning v2) 4.211 3 40.85 - - 3.894 4 45.94
+ KG-Triples
GPT 3.5-turbo
4.338 0 47.18 3.840 5 72.43 4.661 2 79.26
+ KG-Triples
Ours (ChatGLM-6B w/o finetuning) 4.140 8 38.03 3.754 1 60.81 3.943 7 28.67
Ours (ChatGLM-6B p-tuning v2) 4.239 4 42.25 - - 4.311 1 49.60
Ours (GPT 3.5-turbo) 4.528 2 52.82 4.029 7 76.22 4.675 3 79.40
注: 加粗表示同一数据集上的最好结果
在 Aero-QA 数据集上, 本文提出的方法同样取得了最优结果. 在直接使用 ChatGLM-6B 作为基座模型时,
LLM-Score 和 Accuracy 提升分别达到了 0.57 和 7.79%, 而在使用 p-tuning v2 微调后的 ChatGLM-6B 作为基座模
型时, 对应指标的提升同样可以达到 0.418 和 3.66%, 在使用 GPT 3.5-turbo 作为基座模型时, LLM-Score 和
Accuracy 相较于基线提升了 0.014 和 0.14%. 这进一步证明了本文所提方法的有效性.
实验结果表明, 无论是在机械制造领域还是航空航天领域, 本文提出的方法都能显著提升 LLM 的性能. 通过
将检索到的三元组与问题的相关程度输入 LLM, 在多模型与多数据场景下, 使其能够更好地利用证据三元组, 从
而提高其推理能力和回答问题的准确性, 证明了本文提出方法的有效性.
此外, 在 LLM-Score 提升的显著性方面, 观察到 Aero-QA 上的 3 种 LLM 的提升差异性较大. 这可能是因为
Aero-QA 数据集为英文数据集, 且三元组规模较大, 但问题相对简单, 因此在 ChatGLM-6B (w/o finetuning) 以及
ChatGLM-6B (p-tuning v2) 上, 本文提出的方法提升较为显著, 而对于 GPT-3.5 模型, 在基线实验中已经取得了较
好的效果 (4.661 2), 因此本文方法提升幅度较小.
为了更全面地衡量问答模型的性能, 本文引入了用户满意度 CAST 指标, 在 Mecha-QA 数据集上使用 GPT
3.5-turbo 模型的结果如表 6 所示. 随机从 Mecha-QA 的测试集中抽取 100 条数据, 由两位人类专家独立对模型的
k 为 0.771 4. 从表中结果可以发现, 本文提出的方法可以有效提升用户
回复进行评分, 两位专家评分的一致性指标
对问答系统的满意度.
表 6 在 Mecha-QA 数据集上 CAST 实验结果 (%)
模型 CAST
GPT 3.5-turbo + KG-Triples 83
Ours (GPT 3.5-turbo) 87
4.4 消融实验结果分析
本文进行了一系列的消融实验, 以进一步验证 prompt 中三元组与问题的相关程度以及排序模块的有效性. 具
体来说, 为了验证三元组与问题的相关性程度的作用, 在构造 prompt 时, 仅根据三元组的相关性进行排序, 而不将
相关性的具体数值作为 prompt 的内容输入 LLM, 即 w/o score. 为了验证排序模块的作用, 在构造 prompt 时, 仅将
三元组和对应的相关性输入 LLM 而不进行排序, 即 w/o sort. 最终, 若既不输入三元组与问题的具体相关性程度也
不进行排序, 则将乱序三元组直接构建 prompt 输入 LLM, 即 w/o scores & w/o sort. 消融实验的实验结果如表 7 所
示, 将 4 种方式构建的 prompt 在各基座模型和数据集下的表现进行排名, 得到的平均排名如表 8 所示. 表 7 中未
使用 ChatGLM-6B (p-tuning v2) 在 Mecha-QA-3D 上进行实验, 这是因为 Mecha-QA-3D 不包含训练数据, 而该方