
Page 489 - 《软件学报》2025年第8期
P. 489
3912 软件学报 2025 年第 36 卷第 8 期
心运行在 1.8 GHz 下, 双精度浮点峰值性能为 518.4 GFlops. 相比之下, NVIDIA Tesla V100S 的双精度峰值性能则
高达 8.177 TFlops. 为了公平对比, 本文利用公式 10, 通过计算性能效率的比值将不同硬件峰值性能进行归一化.
N/T DSP
P norm = F DSP = T GPU × F GPU (10)
N/T GPU T DSP × F DSP
F GPU
其中, N 代表执行该算子需要的浮点数计算次数, T 代表执行该算子的时间, F 代表对应硬件的浮点数峰值性能.
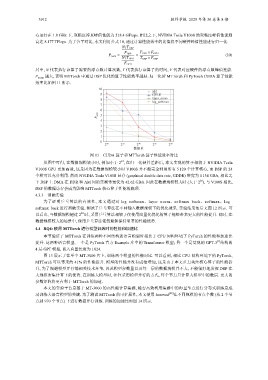
P nor 越大, 表明 MTTorch 中通过 DSP 优化的算子性能效率越好. 归一化后 MTTorch 和 PyTorch CUDA 算子性能
m
效率比如图 11 所示.
10
add
9 GELU
layer_norm
8
log_softmax
7
6
P norm 5
4
3
2
1
0
2 20 2 22 2 24 2 26 2 28
数据量
图 11 CUDA 算子和 MTTorch 算子性能效率对比
24
从图中可得, 在数据规模较小时, 例如小于 2 , 在归一化硬件差距后, 本文实现的算子相较于 NVIDIA Tesla
V100S GPU 更加高效, 这是因为在数据规模较小时 V100S 并不能完全利用所有 5 120 个计算核心, 而 DSP 的 24
个核可以充分利用. 然而 NVIDIA Tesla V100S 显存 (graphical double data rate, GDDR) 带宽为 1 134 GB/s, 相比之
26
下 DSP 上 DMA 在 DDR 和 AM 间的实测带宽仅为 42.62 GB/s. 因此在数据规模较大时 (大于 2 ), 与 V100S 相比,
DSP 的数据访存会成为影响 MTTorch 核心算子性能的瓶颈.
4.3.3 消融实验
为了证明乒乓算法的有效性, 本文通过对 log_softmax、layer_norm、softmax_back、softmax、log_
softmax_back 进行消融实验, 测试了乒乓算法在不同输入数据规模下的优化效果. 实验结果如后文图 12 所示. 可
20
以看出, 当数据规模超过 2 时, 采用乒乓算法相较于仅使用向量化优化的算子能够带来更大的性能提升. 同时, 在
数据规模较大的场景中, 使用乒乓算法依然能够保持显著的性能优势.
4.4 RQ4: 使用 MTTorch 进行模型训练时的性能和加速比
本节验证了 MTTorch 在训练两种不同结构的语言模型时相比于 CPU 同构环境下 PyTorch 的性能和加速比
[1]
提升. 这两种语言模型, 一个是 PyTorch 官方 Example 库中的 Transformer 模型; 另一个是复现的 GPT-3 结构的
4 层 GPT 模型, 嵌入向量长度为 1 024.
图 13 展示了在单个 MT-3000 片上, 训练两个模型的性能对比. 可以看到, 相比 CPU 同构环境下的 PyTorch,
MTTorch 可以带来约 41% 的性能提升. 模型的性能并没有成倍增加, 这是由于本文重点关注核心算子的性能提
升, 为了规避模型并行等相关技术环节, 因此模型参数量以及每一层的数据规模并不大, 不能很好地发挥 DSP 在
大规模密集计算下的优势. 在训练大模型时, 往往采用模型并行的方式, 每个节点只计算大模型中的数层. 更大的
参数矩阵将更有利于 MTTorch 的加速.
本文的实验平台是基于 MT-3000 的高性能计算集群, 能否高效利用集群中的海量节点进行分布式训练是成
功训练大语言模型的关键. 为了测试 MTTorch 的可扩展性, 本文使用 horovod [22] 在不同规模的节点个数 (从 2 个节
点到 970 个节点) 下进行数据并行训练. 训练的加速比如图 14 所示.