
Page 487 - 《软件学报》2025年第8期
P. 487
3910 软件学报 2025 年第 36 卷第 8 期
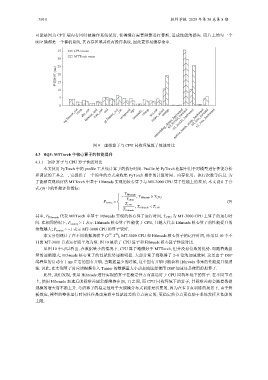
可能是因为 CPU 端内存同时被操作系统使用, 使得缓存需要频繁进行替换, 造成性能的损失. 而片上的每一个
DSP 簇都是一个裸机系统, 其内存区域并没有操作系统, 因此更容易缓存命中.
35 CPU mean
MTTorch mean
30
25
平均时间 (ms) 20
15
10
5
0
eq.Tensot_out norm abs_out max_out ceil gt.Tensor_out _cat reciprocal sqrt bernoulli_ clamp triu.out embedding_dense_backward nll_loss_forward
index_select
bitwise_and
nll_loss_backward
nll_loss2d_backward
native_batch_norm_backward
arange
nll_loss2d_forward
图 9 虚拟算子与 CPU 同构环境算子性能对比
4.3 RQ3: MTTorch 中核心算子的性能提升
4.3.1 DSP 算子与 CPU 算子性能对比
本文使用 PyTorch 中的 profile 工具统计算子的执行时间. Profile 是 PyTorch 框架中用于对模型进行性能分析
和调试的工具之一, 它提供了一个简单的方式来收集 PyTorch 操作的计算时间、内存使用、执行次数等信息. 为
了能够直观地评估 MTTorch 中基于 Hthreads 实现的核心算子与 MT-3000 CPU 算子性能上的差异, 本文设计了公
式 (9) 中的性能评价指标:
T Hthreads
− , T Hthreads ⩾ T CPU
T CPU
P source = (9)
T CPU
, T Hthreads < T CPU
T Hthreads
其中, T Hthread 代表 MTTorch 中基于 Hthreads 实现的核心算子运行时间, T CP 为 MT-3000 CPU 上算子的运行时
U
s
间. 在相同情况下, P source > 1 表示 Hthreads 核心算子性能优于 CPU, 且越大代表 Hthreads 核心算子的性能提升的
倍数越大; P source < −1 表示 MT-3000 CPU 的算子较好.
本文分别统计了在不同数据规模下 (2 –2 ), MT-3000 CPU 和 Hthreads 核心算子的运行时间, 结果以 10 个不
18
28
同的 MT-3000 节点运行取平均为准. 图 10 展示了 CPU 算子和 Hthreads 核心算子性能对比.
从图 10 中可以看出, 在数据量小的情况下, CPU 算子略微好于 MTTorch, 但并没有倍数的优势. 而随着数据
量的逐渐增大, Hthreads 核心算子的性能优势逐渐明显. 大部分算子都取得了 2–8 倍的加速效果. 这是由于 DSP
线程组的启动有 1 ms 左右的固有开销, 当数据量少的时候, 这个固有开销可能会将 Hthreads 带来的性能提升抵消
掉. 因此, 在实现算子时应该根据传入 Tensor 的数据量大小动态地选择使用 DSP 加速还是使用虚拟算子.
此外, 我们发现, 使用 Hthreads 进行实现的算子在稳定性方面要远好于 CPU 同构环境下的算子. 在不同节点
上, 使用 Hthreads 加速后的标准差通常都维持在 [0, 1] 之间, 而 CPU 同构环境下的算子, 其标准差却会随着数据
规模的增大而不断上升. 考虑算子的稳定性对于大规模分布式训练是必要的, 因为在多节点训练的场景下, 由于短
板效应, 模型的整体运行时间往往是由集群中性能最差的节点决定的, 更稳定的节点更有助于系统发挥其性能的
上限.