
Page 491 - 《软件学报》2025年第8期
P. 491
3914 软件学报 2025 年第 36 卷第 8 期
MT-3000 DSP 加速区内存 CPU 可读写的特性, 设计了虚拟算子技术. 这保证了计算图中算子支持完备. 同时, 针对
训练 Transformer 模型过程中的核心算子, 从算子实现向量化、DSP 多核规约算法、乒乓算法等角度介绍了深度
学习算子在 MT-3000 上并行加速的思路和实现, 并取得了 2–8 倍的性能提升. 本文实现的 MTTorch 作为一个原
生 PyTorch 的扩展库, 可以实现不同版本 PyTorch 的即插即用, 新增算子无需修改 PyTorch 源码, 具有很高的可编
程性.
MT CPU
25 000 MTTorch
20 000
时间 (s) 15 000
10 000
5 000
0
Transformer GPT
验证模型
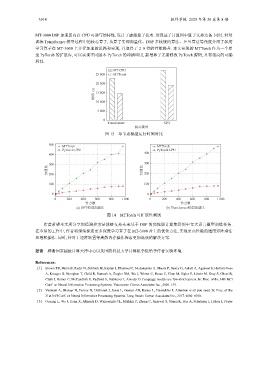
图 13 单节点模型运行时间对比
500
MTTorch MTTorch
PyTorch CPU PyTorch CPU
400
400
300 300
加速比 200 加速比 200
100 100
0 0
0 200 400 600 800 1 000 0 200 400 600 800 1 000
节点数 节点数
(a) GPTଆࡆб (b) Transformerଆࡆб
图 14 MTTorch 可扩展性测试
作者希望本文所分享的经验和方法能够支持未来基于 DSP 的高性能计算集群的中文大语言模型训练任务.
在今后的工作中, 作者将继续探索更多深度学习算子在 MT-3000 片上的优化方法, 实现更高性能的通用矩阵乘法
和卷积操作. 同时, 针对于矩阵转置等离散内存操作探索更加高效的解决方案.
致谢 感谢国家超级计算天津中心以及国防科技大学计算机学院给予作者实验环境.
References:
[1] Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S, Herbert-Voss
A, Krueger G, Henighan T, Child R, Ramesh A, Ziegler DM, Wu J, Winter C, Hesse C, Chen M, Sigler E, Litwin M, Gray S, Chess B,
Clark J, Berner C, McCandlish S, Radford A, Sutskever I, Amodei D. Language models are few-shot learners. In: Proc. of the 34th Int’l
Conf. on Neural Information Processing Systems. Vancouver: Curran Associates Inc., 2020. 159.
[2] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Attention is all you need. In: Proc. of the
31st Int’l Conf. on Neural Information Processing Systems. Long Beach: Curran Associates Inc., 2017. 6000–6010.
[3] Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, Zhang C, Agarwal S, Slama K, Ray A, Schulman J, Hilton J, Fraser