
Page 375 - 《软件学报》2025年第8期
P. 375
3798 软件学报 2025 年第 36 卷第 8 期
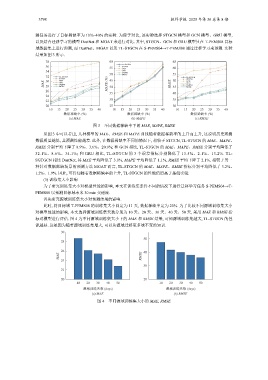
测任务进行了目标稀缺率为 10%–40% 的实验. 为便于对比, 该实验选择 STGCN 模型和 GCN 模型、GRU 模型,
以及结合迁移学习的模型 DastNet 和 MGAT 来进行对比. 其中, STGCN、GCN 和 GRU 模型只在 T-PEMS08 目标
域数据集上进行预测, 而 DastNet、MGAT 以及 TL-STGCN 在 S-PEMS04→T-PEMS08 通过迁移学习来预测. 实验
结果如图 3 所示.
38 60 65
TL-STGCN
36 STGCN
55 GCN 60
34 GRU
DastNet
50 55
32 TL-STGCN MGAT
STGCN 45 50 TL-STGCN
STGCN
GCN
30
GCN
MAE 28 GRU MAPE (%) 40 RMSE 45 GRU
DastNet
DastNet
MGAT
MGAT
26
35 40
24
30 35
22
20 25 30
10 15 20 25 30 35 40 10 15 20 25 30 35 40 10 15 20 25 30 35 40
数据稀缺率 (%) 数据稀缺率 (%) 数据稀缺率 (%)
(a) MAE (b) MAPE (c) RMSE
图 3 不同数据稀缺率下的 MAE, MAPE, RMSE
从图 3 中可以看出, 几种模型的 MAE、RMSE 和 MAPE 曲线随着数据稀缺率的上升而上升, 这说明历史观测
数据质量越低, 其预测性能越差. 此外, 在数据稀缺率不同的情况下, 相较于 STGCN, TL-STGCN 的 MAE、MAPE、
RMSE 分别平均下降了 8.9%、3.6%、20.9%; 和 GCN 相比, TL-STGCN 的 MAE、MAPE、RMSE 分别平均降低了
32.1%、8.6%、34.1%; 和 GRU 相比, TL-STGCN 的 3 个误差指标分别降低了 13.5%、2.1%、13.2%. TL-
SGTGCN 相比 DastNet, 其 MAE 平均降低了 3.0%, MAPE 平均降低了 1.1%, RMSE 平均下降了 2.1%. 相较于另一
种针对数据稀缺场景的预测方法 MGAT 而言, TL-STGCN 的 MAE、MAPE、RMSE 指标分别平均降低了 3.2%、
1.2%、1.9%. 因此, 可得知随着数据稀缺率的上升, TL-STGCN 的性能仍旧高于基线实验.
(3) 训练集大小影响
为了研究训练集大小对模型性能的影响, 本文在训练集条件不同的情况下进行迁移学习任务 S-PEMS04→T-
PEMS08 以预测目标域未来 30 min 交通流.
首先研究源域训练集大小对预测结果的影响.
此时, 将目标域 T-PEMS08 的训练集大小固定为 11 天, 数据稀缺率定为 20%. 为了比较不同源域训练集大小
对模型性能的影响, 本文选择源域训练集天数分别为 10 天、20 天、30 天、40 天、50 天, 采用 MAE 和 RMSE 指
标对模型进行评估. 图 4 为不同源域训练集大小下的 MAE 和 RMSE 结果, 可知源域训练集越大, TL-STGCN 的性
能越好. 这是因为随着源域训练集增大, 可以从源域迁移更多域不变的知识.
30
50
28
MAE 26 RMSE 40
24
30
22
20 20
10 20 30 40 50 10 20 30 40 50
源域训练天数 (days) 源域训练天数 (days)
(a) MAE (b) RMSE
图 4 不同源域训练集大小的 MAE, RMSE