
Page 334 - 《软件学报》2025年第8期
P. 334
赵衔麟 等: 面向代码注释生成任务的注释质量评价研究 3757
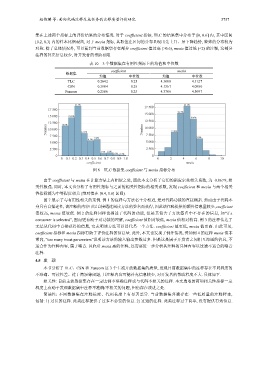
集在上述两个指标上的评价结果的分布情况. 对于 coefficient 指标, TLC 的结果集中分布于 [0, 0.6] 内, 其中区间
[0.2, 0.3] 内的样本比例最高, 对于 mesia 指标, 其取值在区间的分布呈现出先上升、后下降趋势, 整体的分布较为
对称. 除了总体情况外, 可以看到当前数据集存在部分 coefficient 值过高 (>0.6), mesia 值过低 (<2) 的注释, 这部分
注释的补充信息较少, 对开发者的帮助有限.
表 10 3 个数据集在有用性指标上的均值和中位数
coefficient mesia
数据集
均值 中位数 均值 中位数
TLC 0.264 2 0.25 4.308 8 4.312 7
CSN 0.290 4 0.25 4.136 7 4.098 0
Funcom 0.258 6 0.25 4.378 6 4.309 7
27.5% 26.1%
17 500
17 500
22.3%
15 000
15 000 21.2%
19.4%
12 500
12 500 16.6%
Number 10 000 12.5% Number 10 000 12.4%
7 500 7 500
9.2% 9.0%
8.5%
5 000 5 000
2 500 2 500
1.5% 1.8%
0.7% 0.4%
0 0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0 2 4 6 8 10
coefficient mesia
图 6 TLC 数据集 coefficient 与 mesia 指标分布
由于 coefficient 与 mesia 在计算方法上有相似之处, 因此本文分析了它们的斯皮尔曼相关系数, 为−0.867 9, 相
关性极强. 同时, 本文也分析了有用性指标与之前的相关性指标的相关系数, 发现 coefficient 和 mesia 与两个相关
性指标都为中等程度相关 (绝对值在 [0.4, 0.6] 区间).
图 7 展示了与有用性相关的案例. 例 1 的注释与方法名十分相近, 是对代码功能的直接概括. 然而由于代码本
身具有自描述性, 该注释的内容可以直接通过阅读方法的签名而获得, 因此该注释提供的额外信息量较少, coefficient
值较高, mesia 值较低. 例 2 的注释同样也描述了代码的功能, 但是其包含了方法签名中不存在的信息, 如“if a
consumer is selected”, 因而更有助于对功能的理解, coefficient 值相对较低, mesia 值相对较高. 例 3 的注释传达了
无法从代码中直接获得的信息, 它表明该方法可以替代另一个方法. coefficient 值更低, mesia 值更高. 由此可见,
coefficient 指标和 mesia 指标有助于评价注释的信息量. 此外, 本文也发现了例外情况, 譬如例 4 的注释 mesia 值非
常高, “too many inout parameters”说明该方法的输入输出参数过多. 但是这是属于开发者之间相互沟通的信息, 不
适合作为注释内容, 属于噪音. 因此对 mesia 高的注释, 还需要进一步分析其注释的具体内容以过滤不适合的噪音
注释.
4.5 发 现
本节分析了 TLC、CSN 和 Funcom 这 3 个主流开放数据集的质量, 发现目前数据集中的注释存在不同程度的
不准确、可读性差、过于简短等问题, 且注释内容可能补充信息较少, 对开发者的帮助程度不大. 具体如下.
相关性: 目前主流数据集存在一定比例不准确注释或与代码不相关的注释. 本文选取的两项相关性指标一定
程度上有助于发现数据集中注释不准确/不相关的问题, 但仍存在改进之处.
简洁性: 不同数据集在注释长度、代码长度上有显著差异. 当前数据集普遍存在一些低质量的注释样本,
包括: 1) 过长的注释. 此类注释提供了过多不必要的信息. 2) 过短的注释. 此类注释过于简单, 没有提供有效信息.