
Page 333 - 《软件学报》2025年第8期
P. 333
3756 软件学报 2025 年第 36 卷第 8 期
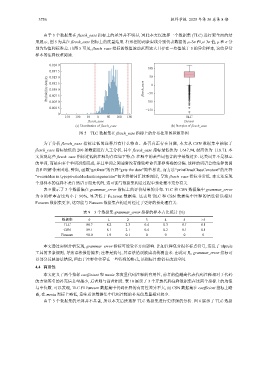
由于 3 个数据集在 flesch_ease 指标上的差异并不明显, 因此本文仅选择一个数据集 (TLC) 进行更全面的结
果展示, 图 5 为其在 flesch_ease 指标上的度量结果. 柱形图的两条虚线分别代表数据的 μ–3σ 和 μ+3σ 值, μ 和 σ 分
别为均值和标准差. 由图 5 可见, flesch_ease 指标的数值波动范围较大且存在一些值低于 0 的异常样本, 这些异常
样本的注释较难阅读.
0.020 0
100
0.017 5 50
Probability density 0.012 5 flesch_ease −50 0
0.015 0
0.010 0
0.007 5
0.005 0 −100
0.002 5
−150
0
−150 −100 −50 0 50 100 150 TLC
flesch_ease Dataset
(a) Distribution of flesch_ease (b) Boxplot of flesch_ease
图 5 TLC 数据集在 flesch_ease 指标上的分布柱形图和箱形图
为了分析 flesch_ease 指标过低的注释具有什么特点、是否真正存在问题, 本文从 CSN 数据集中抽取了
flesch_ease 指标最低的 200 条数据进行人工分析, 其中 flesch_ease 指标最低值为−1 647.94, 最高值为−118.71. 本
文发现这些 flesch_ease 指标过低的注释均存在如下特点: 注释中的某些词包含的字母数过多. 这类词并不是独立
的单词, 而是由多个单词拼接而成, 并且单词之间通常没有像驼峰命名那样明确的分隔. 这样的词语会给注释的阅
读和理解带来困难. 譬如, 函数“getDate”的注释“gets the date”简单易读, 而方法“printDeadClassConstant”的注释
“overridden in typeprivateddeclarationgenerator”包含拼接词汇较难阅读, 导致 flesch_ease 指标非常低. 本文还发现
个别样本的注释不是自然语言而是代码, 这可能与数据集构造过程中预处理不充分有关.
表 9 展示了 3 个数据集在 grammar_error 指标上的评价结果的分布. TLC 和 CSN 数据集中 grammar_error
为 0 的样本占比均小于 90%, 显著低于 Funcom 数据集. 这表明 TLC 和 CSN 数据集中注释的语法错误相对
Funcom 数据集更多, 这可能与 Funcom 数据集在构造时经过了更好的预处理有关.
表 9 3 个数据集 grammar_error 指标的样本占比统计 (%)
数据集 0 1 2 3 4 5 >5
TLC 88.7 8.2 2.3 0.4 0.3 0.1 0.1
CSN 89.1 8.1 2.1 0.4 0.2 0.1 0.1
Funcom 98.0 1.9 0.1 0 0 0 0
本文通过实例分析发现, grammar_error 指标可能受多方面影响. 比如注释包含很多标点符号, 违反了 nlprule
工具的多条规则, 导致语法报错偏多; 注释是病句, 其语法错误被成功检测出来. 由此可见, grammar_error 指标可
以部分反映语法错误, 但由于注释往往存在一些特殊的格式, 该指标目前仍有改进空间.
4.4 有用性
本文定义了两个指标 coefficient 和 mesia 来度量代码注释的有用性, 前者的值越高代表代码注释相对于代码
的方法签名的补充信息量越少, 后者则与前者相反. 表 10 展示了 3 个开放代码注释数据集在这两个指标上的均值
与中位数. 可以发现, TLC 和 Funcom 数据集中代码注释的有用性差异不大, 而 CSN 数据集在 coefficient 指标上略
高, 在 mesia 指标上略低, 意味着该数据集中代码注释的补充信息量相对较少.
由于 3 个数据集的差异并不显著, 所以本文后续选择 TLC 数据集进行更详细的分析. 图 6 展示了 TLC 数据