
Page 330 - 《软件学报》2025年第8期
P. 330
赵衔麟 等: 面向代码注释生成任务的注释质量评价研究 3753
中出现的概率得到的. 基本思想是如果一个词更可能出现在注释中, 说明它更常见, 所带来的额外信息量更少. 同
时, 由于不同的代码与注释长度差异较大, 为了具有可比性, mesia 指标考虑了注释的长度. 由计算方法可以看出,
mesia 指标越高, 相对来说该注释的信息补充程度就越高.
4 主流开放注释数据集的质量分析
本节使用第 3.2 节选取的评价指标对 3 个主流开放代码注释数据集中人工注释的质量进行评价和分析. 下面
详细介绍各个维度上的评价和分析结果.
4.1 相关性
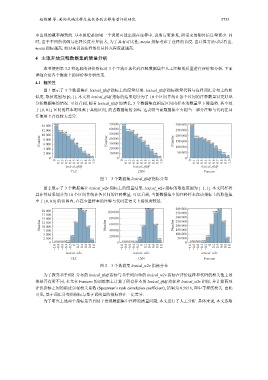
图 1 展示了 3 个数据集在 lexical_tfidf 指标上的度量结果. lexical_tfidf 指标衡量代码与注释词汇分布上的相
似度, 取值范围为 [0, 1]. 本文将 lexical_tfidf 指标的结果划分为了 10 个区间并统计各个区间的注释数量以更好地
分析数据集的情况. 可以看到, 随着 lexical_tfidf 的增长, 3 个数据集在相应区间内样本的数量呈下降趋势. 其中处
于 [0, 0.1] 区间的样本明显高于其他区间, 约占数据集的 20%. 这表明当前数据集中有相当一部分注释与代码在词
汇使用上存在较大差异.
20.8% 70 000 19.3% 300 000 22.3%
14 000
60 000
12 000 16.8% 16.1% 15.5% 250 000
15.7%
10 000 14.7% 50 000 13.5% 200 000 13.9%
Number 8 000 11.5% 8.8% Number 40 000 11.8% 9.5% Number 150 000 13.5% 12.6% 11.3% 9.6%
30 000
6 000
4 000 6.2% 20 000 6.9% 4.5% 100 000 7.4% 5.1%
3.7% 50 000
2 000 1.8% 10 000 2.2% 3.0%
0.6% 0.6% 1.2%
0 0 0
0 0 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
lexical_tfidf lexical_tfidf lexical_tfidf
TLC CSN Funcom
图 1 3 个数据集 lexical_tfidf 指标分布
图 2 展示了 3 个数据集在 lexical_w2v 指标上的度量结果. lexical_w2v 指标的取值范围为 [−1, 1]. 本文同样将
其计算结果划分为 10 个区间并统计各区间的注释数量. 可以看到, 当前数据集中的注释样本在该指标上的取值集
中于 [0, 0.8] 的范围内, 存在少量样本的注释与代码在语义上相似度较低.
30.4% 30.9% 30.6% 400 000 29.7%
20 000 28.7% 100 000 350 000 27.0%
17 500
15 000 80 000 300 000 18.4%
Number 12 500 18.0% 14.4% Number 60 000 15.3% 16.2% Number 200 000 15.6%
250 000
10 000
150 000
7 500
5 000 5.5% 40 000 100 000 4.9%
20 000
2 500 2.4% 4.0% 2.7% 50 000 0.0%0.0%0.0% 0.6% 3.7%
0 0.0%0.0%0.0% 0.7% 0 0.0%0.0%0.0%0.3% 0
−1.0 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1.0 −1.0 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1.0 −1.0 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1.0
lexical_w2v lexical_w2v lexical_w2v
TLC CSN Funcom
图 2 3 个数据集 lexical_w2v 指标分布
为了探究基于词汇分布的 lexical_tfidf 指标与基于词向量的 lexical_w2v 指标在评价注释和代码的相关性上效
果是否有所不同, 本文在 Funcom 的训练集上计算了所有样本的 lexical_tfidf 指标和 lexical_w2v 指标, 并计算两项
评价指标之间的斯皮尔曼相关系数 (Spearman’s rank correlation coefficient), 结果为 0.565 6, 即中等程度相关. 由此
可见, 基于词汇分布的指标与基于词向量的指标存在一定差异.
为了研究上述两个指标是否有助于发现数据集中注释的质量问题, 本文进行了人工分析. 具体来说, 本文选取