
Page 337 - 《软件学报》2025年第8期
P. 337
3760 软件学报 2025 年第 36 卷第 8 期
的平均语法错误数量更少. 低 BLEU 集的平均错误更多. 虽然该指标仍有一定的改进空间, 但该结果也部分说明生
成的注释语句结构通常更简单, 更不容易被现有工具检测出语法错误.
Generate
0.017 5 100
Dataset
Low-BLEU
0.015 0 50
0.012 5 0
Density 0.010 0 −50
0.007 5 −100
−150
0.005 0
0.002 5 −200
−250
0
−250 −200 −150 −100 −50 0 50 100 150 Generate Dataset Low-BLEU
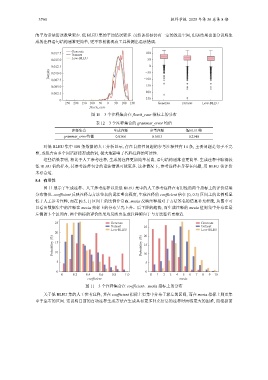
flesch_ease
图 10 3 个注释集合在 flesch_ease 指标上的分布
表 12 3 个注释集合的 grammar_error 均值
注释集合 生成注释 参考注释 低BLEU集
grammar_error均值 0.036 6 0.161 3 0.234 0
对低 BLEU 集中 100 条数据的人工分析显示, 存在自然性问题的参考注释共有 14 条, 主要问题是句子不完
整, 或包含由多个词语拼接形成的词, 极大地影响了代码注释的可读性.
这些结果表明, 相比于人工参考注释, 生成的注释更加简单易读, 语句结构通常也更简单. 生成注释中取得较
低 BLEU 值的样本, 其参考注释包含的语法错误可能更多. 这种情况下, 参考注释本身存在问题, 用 BLEU 值评价
未必合适.
5.4 有用性
图 11 展示了生成注释、人工参考注释以及低 BLEU 集中的人工参考注释在有用性的两个指标上的评价结果
分布情况. coefficient 反映注释与方法签名的词汇重合程度, 生成注释的 coefficient 值在 [0, 0.3) 区间上的比例明显
低于人工参考注释, 而在 [0.5, 1] 区间上的比例非常高. mesia 反映注释相对于方法签名的信息补充程度, 从图中可
以看出数据集中的注释在 mesia 指标上的分布呈先上升、后下降的趋势, 而生成注释的 mesia 值则集中分布在最
左侧的 3 个区间内. 两个指标的评价结果均反映出生成注释倾向于与方法签名更接近.
25 Generate Generate
Dataset 25 Dataset
Low-BLEU Low-BLEU
20 20
Probability (%) 15 Probability (%) 15
10
10
5 5
0 0
0 0.2 0.4 0.6 0.8 1.0 0 1 2 3 4 5 6 7 8 9 10
coefficient mesia
图 11 3 个注释集合在 coefficient、mesia 指标上的分布
关于低 BLEU 集的人工参考注释, 其在 coefficient 指标上更集中分布于靠左的区间, 而在 mesia 指标上则更集
中于靠右的区间. 这说明目前的自动注释生成方法在生成具有更多补充信息的注释时面临更大的困难, 而根据前