
Page 403 - 《软件学报》2025年第5期
P. 403
王晨旭 等: 基于半监督和自监督图表示学习的恶意节点检测 2303
相似度与标签相似度都较高, 所以更需要标签信息来用于区分不同类型的节点.
+
观察 CAMD \ Ba 发现, 去除不平衡损失函数后各数据集的 AUC 分数都有所下降, 这意味着使用不平衡损失函
l
+
数对于恶意检测任务有所帮助, 相对来说 Tencent-Weibo 受不平衡问题影响较大. 此外, 观察 CAMD \ Bal-C 发现,
L
+
在 Amazon 和 YelpChi 数据集上的 AUC 分数下降相对 CAMD \ Ba 较多, 这说明基于类平均的不平衡对比损失在
l
这两个数据集上相对更有效, 而在 Wiki、Tencent-Weibo、T-finance 数据集上, 两种损失函数配合的情况下效果最优.
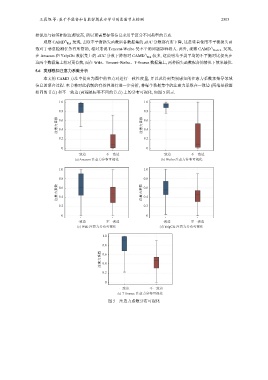
5.6 类别感知注意力系数分析
本文的 CAMD 方法中提出为图中的节点对进行一致性度量, 并以此得到类别感知的注意力系数来指导邻域
信息的聚合过程. 本节将对此机制的有效性进行进一步分析, 将每个数据集中的注意力系数在一致边 (两端是标签
相同的节点) 和不一致边 (两端是标签不同的节点) 上的分布可视化, 如图 5 所示.
1.0 1.0
0.8 0.8
注意力系数 0.6 注意力系数 0.6
0.4
0.4
0.2 0.2
0 0
一致边 不一致边 一致边 不一致边
(a) Amazon 注意力分布可视化 (b) Weibo 注意力分布可视化
1.0 1.0
0.8 0.8
注意力系数 0.6 注意力系数 0.6
0.4
0.4
0.2 0.2
0 0
一致边 不一致边 一致边 不一致边
(c) Wiki 注意力分布可视化 (d) YelpChi 注意力分布可视化
1.0
0.8
注意力系数 0.6
0.4
0.2
0
一致边 不一致边
(e) T-finance 注意力分布可视化
图 5 注意力系数分布可视化