
Page 190 - 《软件学报》2025年第5期
P. 190
2090 软件学报 2025 年第 36 卷第 5 期
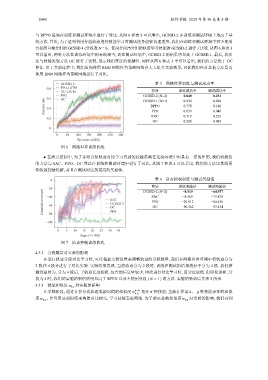
与 RPPO 算法在训练和测试环境中进行了对比. 从图 6 和表 3 可以看出, GCSSD-2 在训练和测试环境上均高于基
线方法. 其次, 为了证明利用分组轨迹进行技能学习对测试任务能够快速适应, 我们在训练和测试环境中对不使用
分段而直接分组的 GCSSD-1 (分段数 N =1)、使用分段再分组的轨迹学习技能的 GCSSD-2 进行了比较. 从图 6 和表 3
可以看出, 两种方法在训练环境中的表现相当, 而在测试环境中, GCSSD-2 的结果明显高于 GCSSD-1. 最后, 我们
还与技能发现方法 OC 进行了比较, 展示我们算法的优越性. 同样从图 6 和表 3 中可以看出, 我们的方法优于 OC
算法. 由于实验过程中, 我们发现使用 RNN 网络作为策略网络会大大提升实验效果, 因此我们也对其他方法是否
使用 RNN 网络作为策略网络进行了对比.
GCSSD-2 表 3 网格世界训练与测试成功率
0.8 PPO-LSTM
OC-LSTM 算法 训练成功率 测试成功率
PPO GCSSD-2 (N=2) 0.840 0.251
0.6
OC
Success rate 0.4 RPPO 0.778 0.180
0.204
GCSSD-1 (N=1)
0.834
0.046
0.059
PPO
ROC 0.719 0.226
0.2
OC 0.208 0.092
0
0 50 100 150 200 250 300
Episodes (×200)
图 6 网格世界训练曲线
● 在质点控制中. 为了证明分组轨迹对比学习得到的技能策略在连续环境中也具有一定的作用, 我们将我们
的方法与 SAC、PPO、OC 算法在训练和测试环境中进行了对比. 从图 7 和表 4 可以看出, 我们的方法比基线更
快收敛到最优解, 并且在测试时达到更高的奖励值.
0 表 4 质点控制训练与测试奖励值
算法
−20 GCSSD-2 (N=2) 训练奖励值 测试奖励值
Cumulative reward −40 SAC SAC −20.912 −73.878
−64.937
−8.519
−8.569
PPO
−84.456
GCSSD-2
−60
−90.562
−97.434
OC
OC
PPO
−80
−100
0 5 10 15 20 25 30 35
Steps (×5 000)
图 7 质点控制训练曲线
4.3.2 分段数量对实验的影响
在进行轨迹分段对比学习时, 可以根据实验设置来调整轨迹的分段数量, 我们在网格世界环境中将轨迹分为
2 段和 4 段并进行了对比实验. 实验结果发现, 当将轨迹分为 2 段时, 训练和测试的结果稍好于分为 4 段. 我们推
测这是因为, 分为 4 段后, 子轨迹长度较短, 包含的信息量较少, 因此进行对比学习时, 区分度较低. 但即使这样, 分
段为 4 时, 我们的实验结果仍然明显高于 RPPO 以及不使用分段 ( N = 1 ) 的方法. 实验结果如后文表 5 所示.
4.3.3 技能相似度 w k,p 对实验的影响
w n 1 ,n 2 k p 种技能表征的相似
在采样阶段, 通过计算分段轨迹奖励均值的相似度 划分 K 种技能, 重新计算第 、
i 1 ,i 2
度 w k,p , 并且用该相似度来构建对比损失, 学习技能表征网络. 为了验证技能相似度 w k,p 对实验的影响, 我们对利