
Page 191 - 《软件学报》2025年第5期
P. 191
杨尚东 等: 基于分组对比学习的序贯感知技能发现 2091
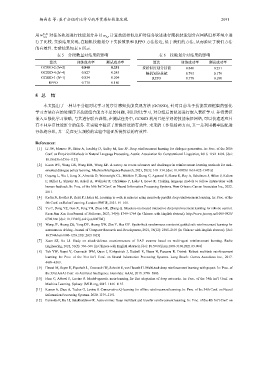
用 w n 1 ,n 2 对任务轨迹进行技能划分并以 w k,p 计算技能相似度和对任务轨迹进行随机技能划分在网格世界环境中进
i 1 ,i 2
行了比较. 实验结果发现, 在随机技能划分下实验效果和 RPPO 方法接近, 低于我们的方法, 从而验证了我们方法
的有效性. 实验结果如表 6 所示.
表 5 分段数量对结果的影响 表 6 技能划分对结果的影响
算法 训练成功率 测试成功率 算法 训练成功率 测试成功率
GCSSD-2 (N=2) 0.840 0.251 按相似度划分技能 0.840 0.251
GCSSD-4 (N=4) 0.827 0.245 随机划分技能 0.795 0.179
GCSSD-1 (N=1) 0.834 0.204 RPPO 0.778 0.180
RPPO 0.778 0.180
5 总 结
本文提出了一种基于分组对比学习的序贯感知技能发现方法 (GCSSD), 针对目前基于技能发现框架的强化
学习方法存在的处理序贯技能组合能力不足的问题, 利用对比学习, 对分组后的轨迹进行嵌入表征学习. 并将表征
嵌入至强化学习策略, 与其进行联合训练, 在测试任务中, GCSSD 利用已经学好的技能表征网络, 可以快速适应具
有不同序贯技能组合的任务. 在实验中验证了所提算法的有效性. 未来的工作包括两方面, 其一是利用概率匹配进
行轨迹分组, 其二是在更大规模的实验中验证所提算法的有效性.
References:
[1] Li JW, Monroe W, Ritter A, Jurafsky D, Galley M, Gao JF. Deep reinforcement learning for dialogue generation. In: Proc. of the 2016
Conf. on Empirical Methods in Natural Language Processing. Austin: Association for Computational Linguistics, 2016. 1192–1202. [doi:
10.18653/v1/D16-1127]
[2] Kwan WC, Wang HR, Wang HM, Wong KF. A survey on recent advances and challenges in reinforcement learning methods for task-
oriented dialogue policy learning. Machine Intelligence Research, 2023, 20(3): 318–334. [doi: 10.1007/s11633-022-1347-y]
[3] Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, Zhang C, Agarwal S, Slama K, Ray A, Schulman J, Hilton J, Kelton
F, Miller L, Simens M, Askell A, Welinder P, Christiano P, Leike J, Lowe R. Training language models to follow instructions with
human feedback. In: Proc. of the 36th Int’l Conf. on Neural Information Processing Systems. New Orleans: Curran Associates Inc., 2022.
2011.
[4] Rudin N, Hoeller D, Reist P, Hutter M. Learning to walk in minutes using massively parallel deep reinforcement learning. In: Proc. of the
5th Conf. on Robot Learning. London: PMLR, 2021. 91–100.
[5] Yu C, Dong YZ, Guo X, Feng YH, Zhuo HK, Zhang Q. Structure-motivated interactive deep reinforcement learning for robotic control.
Ruan Jian Xue Bao/Journal of Software, 2023, 34(4): 1749–1764 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/
6708.htm [doi: 10.13328/j.cnki.jos.006708]
[6] Wang JY, Huang ZQ, Yang DY, Huang XW, Zhu Y, Hua GY. Spatio-lock synchronous constraint guided safe reinforcement learning for
autonomous driving. Journal of Computer Research and Development, 2021, 58(12): 2585–2603 (in Chinese with English abstract). [doi:
10.7544/issn1000-1239.2021.20211023]
[7] Xuan SZ, Ke LJ. Study on attack-defense countermeasure of UAV swarms based on multi-agent reinforcement learning. Radio
Engineering, 2021, 51(5): 360–366 (in Chinese with English abstract). [doi: 10.3969/j.issn.1003-3106.2021.05.004]
[8] Teh YW, Bapst V, Czarnecki WM, Quan J, Kirkpatrick J, Hadsell R, Heess N, Pascanu R. Distral: Robust multitask reinforcement
learning. In: Proc. of the 31st Int’l Conf. on Neural Information Processing Systems. Long Beach: Curran Associates Inc., 2017.
4499–4509.
[9] Hessel M, Soyer H, Espeholt L, Czarnecki W, Schmitt S, van Hasselt H. Multi-task deep reinforcement learning with popart. In: Proc. of
the 33rd AAAI Conf. on Artificial Intelligence. Honolulu: AAAI, 2019. 3796–3803.
[10] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. In: Proc. of the 34th Int’l Conf. on
Machine Learning. Sydney: JMLR.org, 2017. 1126–1135.
[11] Kumar A, Zhou A, Tucker G, Levine S. Conservative Q-learning for offline reinforcement learning. In: Proc. of the 34th Conf. on Neural
Information Processing Systems. 2020. 1179–1191.
[12] Parisotto E, Ba LJ, Salakhutdinov R. Actor-mimic: Deep multitask and transfer reinforcement learning. In: Proc. of the 4th Int’l Conf. on