
Page 167 - 《软件学报》2025年第5期
P. 167
张文跃 等: 基于高斯混合多层自编码器的情感漂移检测模型 2067
是不稳定的, 更容易受到偶然和不可追踪的因素的影响, 例如最近的经历、个人情绪等. 这种不稳定性导致单一用
户、单文档级别的情感不适合指导漂移检测分析. 相反, 由于随机影响因素被中和, 基于多文档进行漂移检测能够
揭示群体在特定时间段内潜在的相对稳定的态度.
本文根据情感数据的时间戳对其进行分割并建立如图 1 所示的多层结构. 在这种结构中, 一组情感数据属于
一个时间段, 几个时间段组成一个窗口, 其中时序情感文档 (表示为 s ) 根据它们所在时间段被分割成块 (表示为 z ),
′
z 表示几个时间段的集合用于表示一段时间窗口内的历史数据.
z
z 1 ′ z 2 ′ z n ′
(1) (1) (1) (2) (2) (2) (n) (n) (n)
s 1 s 2 s L 1 s 1 s 2 s L 2 s 1 s 2 s L n
图 1 依据时间将时序情感文档组织为层次结构
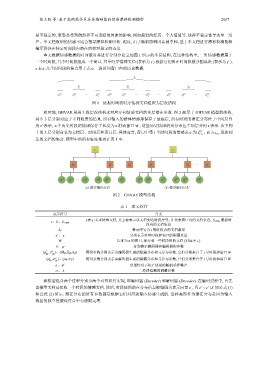
相应地, GHVAE 采用 3 级层次结构来对应序列情感文档的多层潜在参数. 图 2 展示了 GHVAE 模型的结构,
其中 3 层分别对应于不同粒度的信息. 所有输入的群体情感都保存于最底层, 所有时段的潜在分布位于中间层并
′ W , 这些历史情感的元分布位于顶层并用 表示. 从下到
用 z 表示, n 个历史时段的情感保存于长度为 n 滑动窗口 z
上的 3 层分别命名为文档层、时段层和窗口层. 具体而言, 窗口中第 s (i) s 1:L new 是新到
i 个时间段的情感表示为
1:L i , 而
达的文档的集合. 模型中的所有标注都列在表 1 中.
z z
z 1 ′ z 2 ′ ··· z n ′ z 1 ′ z 2 ′ ··· z n ′
(1) (1) (1) (2) (2) (2) (1) (1) (1) (2) (2) (2)
s 1 s 2 s L 1 s 1 s 2 s L 2 s 1 s 2 s L 1 s 1 s 2 s L 1
(a) 模型编码过程 (b) 模型解码过程
图 2 GHVAE 模型结构
表 1 本文标注
表示符号 含义
s表示文本情感文档, 其上标表示该文档到达时段序号, S 代表窗口内的文档集合, S new 是新时
s、S 、S new
段内的文档集合
L i 表示序号为 i 的时段内的文档数量
′
z 、 z 分别表示对应时段和窗口的隐藏变量
W 长度为 n 的窗口, 保存着一些时段组的文档 (对应于 z )
θ、 φ 分别表示解码器和编码器的参数
(µ ,σ )、(M ϕ ,Σ ϕ ,π ϕ ) 两组参数分别表示由编码器生成的隐藏分布和元分布参数, 它们分别来自于 i 号时段和窗口 W
′
′
ϕ i ϕ i
′
(µ ,σ )、(µ θ ,σ θ ) 两组参数分别表示由解码器生成的隐藏分布和元分布参数, 它们分别来自于 i 号时段和窗口 W
′
θ i θ i
′
ε、 ε ′ 分别针对 z 和 z 使用的随机采样噪声
α、 λ 漂移检测的调整参数
新模型包含两个过程分别由两个对应组件实现, 即编码器 (Encoder) 和解码器 (Decoder). 在编码过程中, 首先
′ z ∼ z | S 如公式
′
′
由模型文档层接收一个时段的情感文档. 然后, 时段级的潜在分布信息被编码为表示向量 z , 且 (1)
和公式 (2) 所示. 潜在分布的所有参数都是根据它们对应的输入情感生成的. 选择高斯作为潜在分布是因为输入
数据的独立性假设符合中心极限定理.