
Page 158 - 《软件学报》2025年第5期
P. 158
2058 软件学报 2025 年第 36 卷第 5 期
合, 使模型更全面、深入地捕捉元素间复杂联系, 有利于提升预测准确率, 特别是在不同粒度下更加有效地捕捉交
互关系. 观察实验结果显示, 尽管引入全局位置编码使预测值有所提升, 但在节点数量增多的情况下, 整体准确率
仍然存在下降的问题, 尤其在函数粒度下, 模型难以准确捕捉函数间细微差异. 同时, 版本内的微小变化可能对函
数级别关系产生噪声或干扰, 导致预测准确率下降. 需综合考虑版本内变化和数据规模扩展所带来的影响 [45] , 以
优化模型对函数粒度下的交互关系预测.
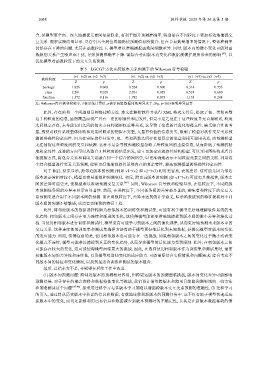
表 5 LGCGT 方法在跨版本关系预测下的 Wilcoxon 符号检验
(v1⇒v2) vs. (v2⇒v3) (v1⇒v2) vs. (v1⇒v3) (v1⇒v3) vs. (v2⇒v3)
软件粒度
Z p Z p Z p
package 1.826 0.068 0.524 0.600 0.314 0.753
class 2.201 0.028 2.201 0.028 0.524 0.600
function 1.572 0.116 1.782 0.075 1.153 0.248
注: Wilcoxon符合秩和检验中, Z表示统计量值, p表示两组数据间的差异水平, Sig. p<0.05表明差异显著
此外, 存在的另一个问题则是网络建模方法. 本文在解析软件并获得 XML 格式文件后, 提取了包、类和函数
这 3 种粒度的信息, 虽然覆盖面较广具有一定的创新性和启发性, 但是不足之处在于这些粒度并无直接联系, 粒度
之间独立存在, 未考虑它们之间的包含方向和调用权重等关系, 这导致了信息的片段化和孤立性. 缺乏综合性的考
量, 致使对软件系统整体结构和元素间联系的把握不完整, 大量有价值的信息丢失, 限制了模型对软件交互关系预
测的准确性和全面性. 因为在实际软件开发中, 包、类和函数之间存在着复杂的嵌套和相互调用关系, 而预测模型
无法捕捉这些粒度间的交互和依赖. 这种不足会导致预测模型忽略了跨粒度间的重要信息, 从而降低了预测的精
度和全局性. 改进的方向可以从整合 3 种粒度的信息出发, 建立更加全面的软件结构模型. 可以采用图结构或者其
他链接方式, 将包含关系和调用关系融合到一个综合的网络中, 以更准确地表示不同粒度元素之间的关联. 利用这
个综合模型进行交互关系预测, 能够更好地捕捉软件系统内在的复杂特性, 提高预测模型的准确性和全面性.
对于 RQ2, 结果显示, 跨邻近版本的预测 (例如 v1⇒v2 和 v2⇒v3) 相对更容易, 表现更好. 这可能是因为邻近
版本的差异相对较小, 模型更容易捕捉和预测变化. 相反, 跨更远版本的预测 (如 v1⇒v3) 可能更具挑战性, 版本之
间的差异可能更大, 使模型难以准确预测交互关系 [46] . 同时, Wilcoxon 符号秩和检验显示, 在包粒度下, 不同跨版
本预测任务间的差异未显示出显著性. 然而, 在类粒度下, 不同任务间的差异是显著的, 意味着类粒度下的交互关
系预测更适合用于不同版本间的预测. 而在函数粒度下, 差异未达到统计学意义, 暗示函数级别的特征提取对不同
版本间的预测不够敏感, 或需要更细致的特征工程.
此外, 将邻近版本的数据选择精细为相邻版本的训练集和测试集, 可能有利于模型更好地理解软件系统的变
化趋势. 相邻版本之间存在更为连续和渐进的变化, 这使得模型能够更准确地捕捉到版本间的微小差异和演化过
程. 当使用相邻版本进行训练和测试时, 模型更有可能学习到版本之间的演化规律, 从而更好地预测未来版本中的
交互关系. 这种连续性的训练集和测试集选择方法有助于模型更好地泛化到未知数据, 并提高模型对版本间变化
的适应能力. 然而, 值得注意的是, 使用相邻版本也可能存在一些挑战. 如果相邻版本之间的变化过于微小或者变
化模式不连续, 模型可能难以捕捉到真正的变化趋势, 从而导致模型的泛化能力受到限制. 此外, 在相邻版本之间
可能存在较大的变化, 这可能使得模型面临更大的挑战. 因此, 在选择使用相邻版本作为训练集和测试集时, 需要
权衡版本间的差异性和连续性, 以及模型对这些变化的适应能力. 可能需要结合实际情况和问题需求, 综合考虑不
同版本间的特征和变化情况, 以找到最适合训练和测试的版本组合.
最后, 总结本文不足, 并期望在后续工作中改进.
(1) 版本间预测问题: 跨邻近版本的预测相对容易, 但跨更远版本的预测面临挑战, 版本间变化差异可能影响
预测结果. 对于存在的概念漂移和数据特性变化等挑战, 我们预计借鉴跨版本和跨项目缺陷预测领域的一些方法
和策略解决这个问题 [47,48] . 拟采用迁移学习与多版本学习策略以增强跨版本交互关系预测的准确性. ① 迁移学习
的引入, 通过将从历史版本中积累的信息和数据, 有效地迁移到新版本的预测任务中. 这不仅有助于模型快速适应
新版本中的变化, 而且还能够利用已有信息和数据减少新版本预测时的不确定性, 尤其是在新版本数据稀缺的情