
Page 156 - 《软件学报》2025年第5期
P. 156
2056 软件学报 2025 年第 36 卷第 5 期
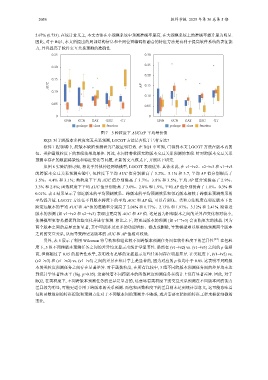
5.67% (0.733). 在统计意义上, 本文方法在小规模系统中预测准确率最高, 在大规模系统上的准确率提升最为明显.
因此, 对于 RQ1, 本文所提出的局部结构信息和全局位置编码相融合的特征方法是有利于提高软件系统的表征能
力, 并且提高了软件交互关系预测的准确性.
0.25 0.30
0.25
0.20
0.20
0.15
AUC AP 0.15
0.10
0.10
0.05
0.05
0 0
GNN GCN GAT GSG GT GNN GCN GAT GSG GT
package class function package class function
图 7 3 种粒度下 AUC/AP 平均增长值
RQ2: 对于跨版本多粒度交互关系预测, LGCGT 方法是否优于已有方法?
软件工程领域中, 跨版本缺陷预测研究已被证明有效. 在 RQ1 中可知, 已得到本文 LGCGT 方法在版本内的
包、类和函数粒度下的表现效果均最佳. 因此, 本问将着重探究跨版本交互关系预测的表现. 针对跨版本交互关系
预测中存在的数据稀缺性和特征变化等问题, 在新的交互模式下, 开展以下研究.
从图 8 实验结果可知, 相比于其他神经网络模型, LGCGT 表现优异. 具体来说, 在 v1⇒v2、v2⇒v3 和 v1⇒v3
的跨版本交互关系预测实验中, 包粒度下平均 AUC 值分别提高了 5.2%、5.1% 和 3.7, 平均 AP 值分别提高了
3.5%、4.4% 和 3.1%; 类粒度下平均 AUC 值分别提高了 3.7%、3.8% 和 3.5%, 平均 AP 值分别提高了 2.9%、
3.3% 和 2.8%; 函数粒度下平均 AUC 值分别提高了 3.0%、2.0% 和 1.9%, 平均 AP 值分别提高了 1.0%、0.3% 和
0.01%. 表 4 结果显示了邻近版本的平均预测效果、跨版本的平均预测效果和邻近版本相较于跨版本预测效果的
平均提升值. LGCGT 方法在不同版本跨度下的平均 AUC 和 AP 值, 可以看到包、类和方法粒度在邻近版本下比
跨更远版本的平均 AUC 和 AP 值的准确率分别高了 2.08% 和 0.77%、2.13% 和 1.97%、3.12% 和 2.41%. 跨邻近
版本的预测 (如 v1⇒v2 和 v2⇒v3) 表现出更高的 AUC 和 AP 值. 这是因为相邻版本之间的差异和变化相对较小,
使得模型更容易捕捉到这些变化并进行预测. 相比之下, 跨更远版本的预测 (如 v1⇒v3) 会面临更大的挑战. 因为
两个版本之间的差异更加显著, 其中可能涉及更多的功能增加、修改或删除, 导致模型难以准确地预测两个版本
之间的交互关系, 从而导致跨更远版本的 AUC 和 AP 值相对较低.
另外, 表 5 展示了利用 Wilcoxon 符号秩和检验比较不同跨版本预测任务间在软件粒度下的差异性 [44] . 在包粒
度下, 3 组不同跨版本预测任务之间的差异均未显示出统计学显著性. 虽然在 (v1⇒v2) vs. (v1⇒v3) 之间的 p 值稍
高, 但都超过了 0.05 的显著性水平, 表明没有足够的证据显示这些任务间存在明显差异. 在类粒度下, (v1⇒v2) vs.
(v2⇒v3) 和 (v1⇒v2) vs. (v1⇒v3) 之间的差异在统计学上是显著的, 因为对应的 p 值均小于 0.05. 这表明不同跨版
本的类粒度预测任务之间存在显著差异. 对于函数粒度, 在所有比较中, 3 组不同跨版本预测任务间的差异均未达
到统计学显著性水平 (Sig. p>0.05). 这意味着不同跨版本的函数粒度预测任务在统计上没有显著差异. 因此, 对于
RQ2, 在类粒度下, 不同跨版本预测任务的差异是显著的, 这意味着类粒度下的交互关系预测在不同版本间的能力
差异较为明显, 可能更适合用于跨版本的关系预测. 而包和函数粒度下的差异则未达到统计学意义, 这可能意味着
包和函数级别的特征提取和预测方法对于不同版本间的预测并不敏感, 或者需要更精细的特征工程来捕捉细微的
变化.