
Page 340 - 《软件学报》2025年第4期
P. 340
1746 软件学报 2025 年第 36 卷第 4 期
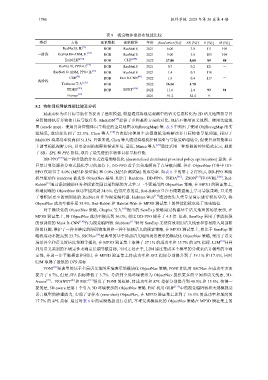
表 9 视觉物体重排布性能比较
类型 方法 视觉数据 视觉模块 年份 fixed strict (%)↑ SR (%)↑ E (%)↓ M (%)↓
ResNet18, IL [13] RGB ResNet18 2021 6.00 3.0 111 109
一阶段 ResNet18+ANM, IL [13] RGB ResNet18 2021 9.00 3.0 105 104
EmbCLIP [118] RGB CLIP [120] 2022 17.00 8.00 89 88
[13]
ResNet18, PPO+IL RGB ResNet18 2021 0.7 0.2 121 -
[13]
ResNet18+ANM, PPO+IL RGB ResNet18 2021 1.4 0.3 110 -
[78] [80]
CSR RGB Fast R-CNN 2022 1.9 0.4 117 -
两阶段
Trabucco等人 [122] RGB - 2022 16.56 4.70 - -
[123] [136]
TIDEE RGB DERT 2022 11.6 2.4 93 94
Human [13] - - 2021 91.2 83.4 9 -
5.2 物体目标导航性能比较及分析
MultiON 为多目标导航任务提出了基准模型, 模型通过将视觉观测中的语义信息转化为 2D 语义地图指导具
验证集上将成功率和
身智能体执行多物体目标导航任务. MultiON [25] 提供了多种基准方案的对比, 包括不使用语义地图、使用先验地
图 (oracle map)、使用具身智能体自主构建的全局地图 (ObjRecogMap) 等. 表 5 中列出了使用 ObjRecogMap 的实
验结果, 成功率达到了 22.0%. Chen 等人 [30] 首次提出使用主动摄像机策略解决多目标物体导航问题, 相对于
MultiON 将成功率提高到 51.1%. 具体来说, Chen 等人通过将相机控制策略与导航策略相结合, 促使具身智能体自
主调节相机视野方向, 以更全面的观察和探索环境. 最近, Marza 等人 [29] 通过采用一种新颖的神经隐式表示, 刷新
了 SR、SPL 和 PPL 指标, 取得了最先进的多物体目标导航性能.
DD-PPO [103] 是一种分散的分布式近端策略优化 (decentralized distributed proximal policy optimization) 算法. 在
巨量计算资源和分布式强化学习的加持下, DD-PPO 近乎完美地解决了点导航问题. 但在 ObjectNav 任务中 DD-
PPO 仅取得了 8.0% (MP3D 验证集) 和 0.0% (MP3D 测试集) 的成功率. 如表 6 中的第 1–2 行所示, DD-PPO 和随
机导航动作 (random) 被选作 ObjectNav 基准. 相比于 Random、DD-PPO、THDA [46] 、ZSON [53] 和 OVRL [108] , Red-
Rabbit [31] 通过添加辅助任务和探索奖励以端到端的方式学习一个更通用的 ObjectNav 策略, 在 MP3D 的验证集上,
将端到端的 ObjectNav 成功率提高到 34.6%. 值得注意的是, Red-Rabbit 只在有限数据集上学习导航策略, 只采用
了卷积层更少的预训练的 ResNet18 作为视觉编码器. Habitat-Web [14] 通过收集人类专家演示进行模仿学习, 将
ObjectNav 成功率提升至 35.4%. Red-Rabbit 和 Habitat-Web 在 MP3D 测试集上的性能指标也处于领先地位.
对于模块化的 ObjectNav 策略, Chaplot 等人 [45] 提出的 SemExp 策略通过构建基于语义地图的场景表示, 在
MP3D 验证集上, 将 ObjectNav 成功率提高到 36.0%, 相比 DD-PPO 提升了 4.5 倍. 但是, SemExp 采用了性能较强
的预训练的 Mask R-CNN [130] 作为视觉编码器. Stubborn [111] 针对 SemExp 无法有效利用语义线索和容易陷入局部陷
阱的问题, 维护了一种多维度的障碍物地图和一种不依赖语义的探索策略, 在 MP3D 测试集上, 相比于 SemExp 策
略将成功率提高到 23.7%. SSCNav [18] 是典型的基于局部语义地图场景表示的模块化 ObjectNav 策略, 采用了语义
场景补全和语义置信度预测等模块, 在 MP3D 验证集上取得了 27.1% 的成功率和 15.7% 的 SPL 指标. L2M [19] 同样
利用语义类别的不确定性来确定长期导航目标, 不同之处在于, L2M 通过集成多个模型的分歧来估计模型的不确
定性, 并进一步平衡探索和利用, 在 MP3D SPL 指标分别提升到了 39.1% 和 17.0%, 同时
L2M 取得了最低的 DTS 指标.
[20]
PONI 是典型的基于全局语义地图环境表示的模块化 ObjectNav 策略, PONI 相比对 SSCNav 在成功率方面
提升了 0.7%, 但是 SPL 指标降低了 3.7%. 考虑到全局环境表示为 ObjectNav 提供更多的空间和语义线索, 3D-
Aware [22] 、PEANUT [41] 和 ESC [113] 沿用了 PONI 的框架, 将成功率和 SPL 指标分别提升到 40.5% 和 15.8%. 值得一
提的是, 3D-aware 是第 1 个引入 3D 环境表示的 ObjectNav 策略. ESC 利用 GLIP [133] 中的视觉编码器和大规模视觉
语言模型的推理能力, 实现了零样本 (zero-shot) ObjectNav, 在 MP3D 验证集上达到了 36.1% 的成功率和最高的
17.7% 的 SPL 指标. 通过对表 6 中的实验数据进行总结, 不难发现模块化的 ObjectNav 策略在 MP3D 验证集上的