
Page 224 - 《软件学报》2025年第4期
P. 224
1630 软件学报 2025 年第 36 卷第 4 期
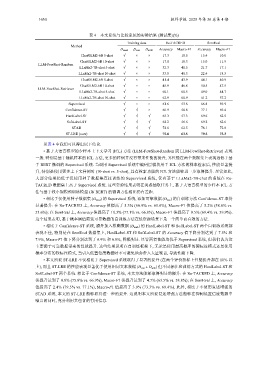
表 4 本文系统与比较系统的实验结果 (测试集)(%)
Training data Re-TACRED SemEval
Method
D seed D con D amb Accuracy Macro-F1 Accuracy Macro-F1
ChatGLM2-6B 5-shot √ × × 17.3 18.8 15.4 10.8
ChatGLM2-6B 10-shot √ × × 17.8 18.3 15.0 11.9
LLM-FewShot-Random
LLaMa2-7B-chat 5-shot √ × × 32.3 41.5 21.7 17.1
LLaMa2-7B-chat 10-shot √ × × 33.8 40.3 22.4 18.3
ChatGLM2-6B 5-shot √ × × 41.4 43.9 44.1 40.9
ChatGLM2-6B 10-shot √ × × 45.9 46.8 50.5 47.5
LLM-FewShot-Retriever
LLaMa2-7B-chat 5-shot √ × × 60.1 60.5 49.0 44.7
LLaMa2-7B-chat 10-shot √ × × 62.9 60.9 61.2 57.2
Supervised √ × × 61.6 53.6 66.8 59.9
Confidence-ST √ √ × 66.9 58.8 77.1 69.4
的性能表现显著优于使用相同文本数据
HardLabel-ST √ √ √ 65.3 57.3 69.6 62.5
SoftLabel-ST √ √ √ 64.2 56.6 69.2 62.6
STAD √ √ √ 74.6 62.5 78.1 72.0
ST-LRE (ours) √ √ √ 75.8 63.5 79.5 73.3
从表 4 中我们可以得出以下结论.
• 基于大语言模型的少样本上下文学习 (ICL) 方法 (LLM-FewShot-Random 或 LLM-FewShot-Retriever) 表现
一般. 特别是基于随机样本的 ICL 方法, 更多的样例并没有带来性能的提升, 其性能在两个数据集上表现远低于基
于 BERT 微调的 Supervised 系统. 当调用 Supervised 系统中编码层模块用于 ICL 方法的样本检索后, 性能显著提
升, 特别是使用更多上下文样例时 (10-shot vs. 5-shot), 具有检索功能的 ICL 方法能够进一步取得提升. 尽管如此,
大部分结果仍低于仅使用种子数据集直接训练的 Supervised 系统, 仅有基于 LLaMa2-7B-chat 的系统在 Re-
TACRED 数据集上高于 Supervised 系统. 这些实验结果表明在关系抽取任务上, 基于大语言模型的少样本 ICL 方
法与基于较小规模预训练模型 (如 BERT) 的微调方法相比仍有差距.
(D seed ) 的 Supervised (D con ) 的自训练方法 Confidence-ST 取得
• 相比于仅使用种子数据集 系统, 添加可靠数据
显著提升: 在 Re-TACRED 上, Accuracy 值提高了 5.3% (66.9% vs. 61.6%), Macro-F1 值提高了 5.2% (58.8% vs.
53.6%); 在 SemEval 上, Accuracy 值提高了 10.3% (77.1% vs. 66.8%), Macro-F1 值提高了 9.5% (69.4% vs. 59.9%).
这个结果表明, 基于概率阈值筛选可靠数据的自训练方法在低资源场景下是一个简单而有效的方法.
• 相比于 Confidence-ST 系统, 额外加入模糊数据 (D amb ) 的 HardLabel-ST 和 SoftLabel-ST 两个自训练系统都
表现不佳, 特别是在 SemEval 数据集上, HardLabel-ST 和 SoftLabel-ST 的 Accuracy 值下降分别达到了 7.5% 和
7.9%, Macro-F1 值下降分别达到了 6.9% 和 6.8%, 降幅明显. 尽管两者性能均优于 Supervised 系统, 但我们认为这
主要源于可靠数据带来的性能提升. 这些结果说明在自训练框架下, 无论是使用最高概率的硬标注模式还是使用
概率分布的软标注模式, 当引入低置信度数据时不可避免地会带入大量噪音, 导致性能下降.
• 本文所提 ST-LRE 不仅相比于 Supervised 系统取得了显著的提升 (在两个评价指标上性能提升都在 10% 以
上), 而且 ST-LRE (D con + D amb ) 但不同标注和训练方式的 HardLabel-ST 和
SoftLabel-ST 两个系统. 相比于 Confidence-ST 系统, 本文方法能够取得明显的提升: 在 Re-TACRED 上, Accuracy
值提升达到了 8.9% (75.8% vs. 66.9%), Macro-F1 值提升达到了 4.7% (63.5% vs. 58.8%); 在 SemEval 上, Accuracy
值提高了 2.4% (79.5% vs. 77.1%), Macro-F1 值提高了 3.9% (73.3% vs. 69.4%). 此外, 相比于不使用复述增强的
STAD 系统, 本文的 ST-LRE 能够取得进一步的提升. 这说明本文所提复述增强方法能够在抑制低置信度数据中
噪音的同时, 充分利用其包含的有用信息.