
Page 208 - 《软件学报》2025年第4期
P. 208
1614 软件学报 2025 年第 36 卷第 4 期
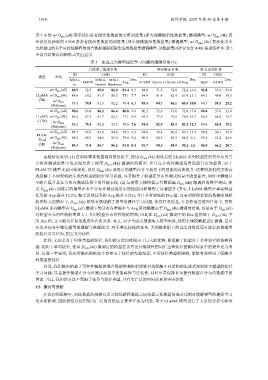
表 3 中的 w/ D pro (all) 表示使用带有提示性数据的完整训练集 (即大规模提示性数据集) 微调模型; w/ D pro (4k) 表
示使用仅抽取的 4 000 条带有提示性数据的训练集 (即小规模提示性数据集) 微调模型; w/ D mix (4k) 表示使用本
文所提出的基于可控性解释的混合数据增强框架生成的数据集微调模型, 该数据集同样仅包含 4 000 条训练样本. 表 3
中最佳结果以加粗形式突出显示.
表 3 生成式大模型捷径学习问题的缓解结果 (%)
自然语言推理任务 事实验证任务 释义识别任务
ID OOD ID OOD ID OOD
模型 方法
MNLI- HANS MNLI- MNLI- Avg. Dec. FEVER Symm.v1 Symm.v2 Avg. Dec. QQP PAWS Dec.
m Hard-m Hard-mm
w/ D pro (all) 89.9 72.3 85.8 86.0 81.4 8.5 88.8 71.5 72.8 72.2 16.6 92.8 53.8 39.0
LLaMA w/ D pro (4k) 84.8 69.2 81.5 80.5 77.1 7.7 94.9 81.4 82.4 81.9 13.1 84.1 49.6 34.5
(7B)
w/ D mix
85.8 74.8 81.3 82.2 79.4 6.3 95.4 84.7 86.1 85.4 10.0 84.5 59.3 25.2
(4k)(ours)
w/ D pro (all) 90.6 69.8 86.2 86.4 80.8 9.8 90.2 72.6 73.0 72.8 17.4 89.4 57.0 32.4
LLaMA w/ D pro (4k) 86.0 67.3 81.7 82.3 77.1 8.9 95.3 77.9 79.6 78.8 16.7 84.5 64.8 19.7
2 (7B)
w/ D mix 86.2 70.1 82.4 83.2 78.6 7.6 95.4 82.9 83.4 83.2 12.3 84.6 65.4 19.2
(4k)(ours)
w/ D pro (all) 87.7 66.9 83.8 84.8 78.5 9.2 94.0 79.4 80.8 80.1 13.9 90.2 50.3 39.9
FLAN-
w/ D pro (4k) 88.8 68.7 84.6 85.4 79.6 9.2 90.9 84.3 85.3 84.8 6.1 85.8 61.2 24.6
T5-xl
(3B) w/ D mix 89.3 71.0 85.7 86.2 81.0 8.4 95.7 90.5 89.9 90.2 5.5 86.9 66.2 20.7
(4k)(ours)
实验结果表明: (1) 在训练样本数量相同的情况下, 使用 D mix (4k) 训练后的 LLaMA 系列模型在所有分布内与
分布外测试场景中的表现均优于使用 D pro (4k) 微调后的模型, 并且在分布外测试场景的提升更为显著. 对于
FLAN-T5 模型来说同样如此, 使用 D mix (4k) 训练后的模型在各个场景下的性能均有所提升. 这表明我们的方法有
效缓解了不同架构的生成式模型的捷径学习问题, 显著提升了模型在分布外测试场景中的鲁棒性, 同时未牺牲甚
至略有提升其在分布内测试场景中的性能表现. (2) 与使用大规模提示性数据集 D pro (all) 微调后的模型相比, 使
用 D mix (4k) 训练后的模型在多个分布外测试场景中的性能同样得到了显著提升 (其中, LLaMA 模型在事实验证
任务的 Avg.提升 13.2%, 释义识别任务的 Avg.提升 5.5%), 并且具有较低的 Dec.值. 这表明即使在训练数据的规模
相差较大的情况下, D mix (4k) 依然有效缓解了模型的捷径学习问题. 值得注意的是, 在自然语言推理任务中, 虽然
LLaMA 系列模型在 D pro (all) 微调下的分布内准确率与 Avg.值均略微高于 D mix (4k) 微调的结果, 但是由于 D pro (all)
对模型分布内性能的增益大于其对模型分布外性能的增益, 因此在 D pro (all) 微调下的 Dec.值仍低于 D mix (4k) 下
的 Dec.值, 这可能与任务的难度也有所关系. 总之, 对于生成式预训练大模型来说, 使用小规模数据进行微调, 足以
在众多任务中激发模型的理解与推理能力. 对于难度较低的任务, 大规模数据下的过度训练反而可能会加重模型
的捷径学习行为, 损害其鲁棒性.
此外, 无论是对于何种类型的捷径, 我们的方法均体现出了巨大的优势, 即缓解了模型对于多种捷径的依赖问
题. 相比于单句捷径, 使用 D mix (4k) 微调后的模型在含有更具挑战性的词汇重叠捷径的测试场景中的提升更为明
显. 这进一步表明, 我们所提出的框架不需要关于捷径的先验知识, 不受捷径类型的限制, 能够有效应用于缓解多
种类型的捷径.
因此, 我们提出的基于可控性解释的混合数据增强框架能够有效缓解不同架构的生成式预训练大模型的捷径
学习问题, 显著提升模型在分布外测试场景中的鲁棒性与泛化性, 同时尽量保持甚至提升模型在分布内数据中的
性能. 并且, 我们的方法不受限于任务与捷径类型, 具有更广泛的应用前景和实用价值.
3.5 探讨与分析
在我们的框架中, 训练数据的规模以及可控性解释数据与原始提示性数据的混合比例对缓解模型的捷径学习
均有所影响. 因此我们以使用较为广泛的自然语言推理任务为代表, 基于 LLaMA 模型进行了大量的分析实验来