
Page 99 - 《软件学报》2024年第4期
P. 99
周植 等: 面向开集识别的稳健测试时适应方法 1677
表 1 存在不同协变量偏移程度的 CIFAR10 数据集上的性能对比(%)
偏移程度=3 偏移程度=5
对比方法
Close-set Acc AUROC OSCR Close-set Acc AUROC OSCR
MLS 79.92±0.00 77.17±0.00 66.82±0.00 70.17±0.00 70.58±0.00 55.96±0.00
ARPL 70.45±0.22 71.60±0.31 56.70±0.32 55.86±0.30 63.52±0.75 42.10±0.49
ARPL+cs 70.57±0.21 71.77±0.56 56.97±0.38 56.18±0.46 64.03±0.41 42.59±0.40
Proser 74.27±0.93 72.17±1.37 59.55±1.60 58.10±1.11 64.26±1.18 43.39±1.25
SC-OSG 72.27±0.75 70.67±1.81 57.77±0.72 55.68±1.38 60.79±1.72 41.05±0.66
BN Stats 79.55±0.04 77.46±0.06 66.77±0.07 75.72±0.04 74.58±0.03 62.12±0.03
Tent 46.18±11.29 48.04±10.25 21.95±3.09 53.34±9.48 54.21±7.03 30.29±7.41
EATA 79.89±0.07 77.18±0.13 66.80±0.13 75.99±0.08 74.44±0.08 62.23±0.05
LAME 77.37±0.09 66.77±0.12 57.40±0.15 72.34±0.06 62.99±0.07 51.33±0.10
CoTTA 40.31±0.53 71.48±1.17 29.98±0.34 37.95±0.83 70.30±1.11 28.00±0.63
OTA 82.14±0.02 80.02±0.03 70.77±0.02 77.45±0.07 75.58±0.07 64.21±0.07
表 2 存在不同协变量偏移程度的 CIFAR100 数据集上的性能对比(%)
偏移程度=3 偏移程度=5
对比方法
Close-set Acc AUROC OSCR Close-set Acc AUROC OSCR
MLS 51.30±0.00 62.08±0.00 39.09±0.00 38.08±0.00 58.54±0.00 28.60±0.00
ARPL 44.81±0.53 58.77±0.28 32.59±0.31 31.48±0.52 56.17±0.29 22.72±0.34
ARPL+cs 45.31±0.59 58.58±0.33 32.87±0.47 32.08±0.66 56.24±0.23 23.16±0.55
Proser 46.63±0.90 62.79±0.68 36.37±0.70 31.01±0.83 58.44±0.54 23.59±0.60
SC-OSG 46.61±0.87 60.86±0.39 35.44±0.79 30.50±0.94 56.77±0.45 22.94±0.91
BN Stats 56.09±0.06 63.94±0.03 43.16±0.04 49.78±0.03 61.89±0.02 37.96±0.03
Tent 25.03±2.82 54.68±0.61 17.05±2.08 15.82±2.77 53.26±0.88 10.59±2.01
EATA 58.58±0.05 64.54±0.07 44.95±0.05 52.40±0.15 62.49±0.09 39.81±0.14
LAME 55.94±0.05 63.77±0.10 43.77±0.04 49.48±0.06 61.17±0.07 37.92±0.08
CoTTA 10.50±0.34 51.36±0.77 6.91±0.19 9.28±0.17 51.52±0.46 6.11±0.08
OTA 59.45±0.06 65.33±0.03 47.06±0.04 53.89±0.05 63.13±0.04 41.93±0.03
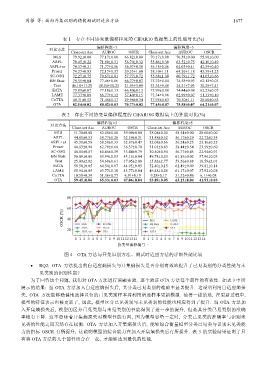
OSCR (%)
协变量偏移编号
图 4 OTA 方法与开集识别方法、测试时适应方法的详细性能比较
• RQ2: OTA 方法提出的自适应熵损失与开集熵损失是否分别有效地提升了已见类别的分类性能与未
见类别的识别性能?
为了回答这个问题, 我们对 OTA 方法进行消融实验, 逐个验证 OTA 方法每个部件的有效性. 如表 3 中所
展示的结果: 当 OTA 方法加入自适应熵损失后, 其分类已见类别的准确率显著提升. 这说明利用自适应熵损
失, OTA 方法能够稳健地选择置信的已见类别样本并利用所选样本更新模型. 值得一提的是, 在更新过程中,
模型的特征表示也被更新了, 因此, 模型区分已见类别与未见类别的性能也相应得到了提升. 当 OTA 方法加
入开集熵损失后, 模型的区分已见类别与未见类别的性能得到了进一步的提升, 但是其分类已见类别的准确
率略有下降. 这不意味着开集熵损失对模型性能有害, 因为模型容量一定时, 分类已见类的准确率与识别未
见类的性能之间天然存在权衡. OTA 方法加入开集熵损失后, 能够综合衡量模型分类已见类与识别未见类能
力的指标 OSCR 有所提升, 这说明模型的综合能力在加入开集熵损失后有所提升. 表 3 的实验结果证明了只
有将 OTA 方法的几个部件组合在一起, 才能够达到最优的性能.