
Page 278 - 《软件学报》2021年第12期
P. 278
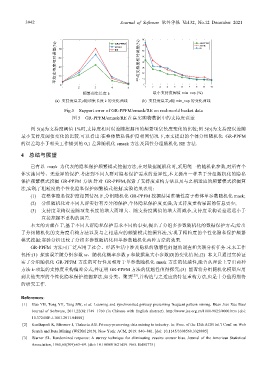
3942 Journal of Software 软件学报 Vol.32, No.12 December 2021
平均支持度相对误差(%) 平均支持度相对误差(%)
频繁项集长度 k 最小支持度阈值 min_sup (%)
(a) 支持度误差ρ随项集长度 k 的变化曲线 (b) 支持度误差ρ随 min_sup 的变化曲线
Fig.5 Support error of GR-PPFM/emask/RE on real-world basket data
图 5 GR-PPFM/emask/RE 在真实购物数据中的支持度误差
图 5(a)为支持度阈值 1%时,支持度相对误差随挖掘出的频繁项集长度变化的比较;图 5(b)为支持度误差随
最小支持度阈值变化的比较.可以看出:在整体隐私保护度相同情况下,本文提出的个体分组随机化 GR-PPFM
的误差均小于相关工作提到的 0,1 差异随机化 emask 方法及属性分组随机化 RE 方法.
4 总结与展望
已有以 mask 为代表的隐私保护频繁模式挖掘方法,在对数据随机化时,采用统一的随机化参数,对所有个
体实施同等、无差异的保护.考虑到不同人群对隐私保护需求的差异性,本文提出一种基于分组随机化的隐私
保护频繁模式挖掘 GR-PPFM 方法.针对 GR-PPFM,探索了支持度重构方法以及与之相适应的频繁模式挖掘算
法,实现了粗粒度的个性化隐私保护频繁模式挖掘.实验结果表明:
(1) 在整体隐私保护度相同情况下,分组随机化 GR-PPFM 挖掘结果准确性高于整体单参数随机化 mask;
(2) 分组随机化对不同人群实行有差异的保护,个体隐私保护度更强,为支持度重构暴露的信息更少;
(3) 支持度重构误差随项集长度的增大而增大、随支持度阈值的增大而减小,支持度重构误差远远小于
直接挖掘不重构的误差.
本文的贡献在于,基于不同人群隐私保护需求不同的事实,提出了分组多参数随机化的数据保护方式;给出
了分组随机化的支持度重构方法以及与之相适应的频繁模式挖掘算法,实现了粗粒度的个性化隐私保护频繁
模式挖掘;实验分析比较了分组多参数随机化和单参数随机化两种方法的效果.
GR-PPFM 方法可广泛应用于社会、经济生活中涉及隐私的敏感性问题的调查和关联分析任务.未来工作
包括:(1) 探索误差随分组参数 w、随机化概率参数 p 和数据集大小参数|D|的变化情况;(2) 本文只通过实验证
实了分组随机化 GR-PPFM 方法的可行性及相对于单参数随机化 mask 方法的优越性,能否从理论上导出两种
方法 k-项集的支持度重构偏差公式,并证明 GR-PPFM 方法的优越性值得探究;(3) 能否将分组随机化模型应用
到其他类型的个性化隐私保护挖掘算法,如分类、聚类 [23] ,并构造与之适应的特征重构方法,也是十分值得期待
的研究工作.
References:
[1] Guo YH, Tong YH, Tang SW, et al. Learning and synchronized privacy preserving frequent pattern mining. Ruan Jian Xue Bao/
Journal of Software, 2011,22(8):1749−1760 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/4000.htm [doi:
10.3724/SP.J.1001.2011.04000]
[2] Kenthapadi K, Mironov I, Thakurta AG. Privacy-preserving data mining in industry. In: Proc. of the 12th ACM Int’l Conf. on Web
Search and Data Mining (WSDM 2019). New York: ACM, 2019. 840−841. [doi: 10.1145/3308560.3320085]
[3] Warner SL. Randomized response: A survey technique for eliminating evasive answer bias. Journal of the American Statistical
Association, 1965,60(309):63−69. [doi: 10.1080/01621459.1965.10480775]