
Page 273 - 《软件学报》2021年第12期
P. 273
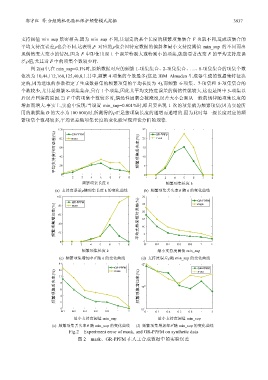
郭宇红 等:分组随机化隐私保护频繁模式挖掘 3937
支持阈值 min_sup 紧密相关.因为 min_sup 不同,其划定的某个长度的频繁项集集合 F 也就不同,造成该集合的
平均支持度误差ρ也会不同.这表明,F 对应的ρ值会因特定数据的偏斜和最小支持度阈值 min_sup 的不同而出
现偶然变大变小的情况.因为 F 中即使出现 1 个误差特别大或特别小的项集,就能显著改变 F 的平均支持度误
差ρ值,尤其当 F 中的项集个数较少时.
图 2(a)中,在 min_sup=0.1%时,原始数据对应的频繁 1-项集集合、2-项集集合、…、8-项集集合的项集个数
依次为 10,44,112,160,125,40,8,1.其中,频繁 4 项集的个数最多(这是 IBM Almaden 生成器生成的数据集特征决
定的,因为选取的参数指定了生成数据集的频繁项集的平均长度为 4),而频繁 6-项集、7-项集和 8-项集集合的
个数较少,尤其是频繁 8-项集集合,只有 1 个项集,因此其平均支持度误差的偶然性就较大,这也是图中 5-项集以
后误差回落的原因.当 F 中的项集个数较多时,偶然性因素会被淹没,误差大小会顺从一般的规律随项集长度的
增加而增大.事实上,实验中发现:当设置 min_sup=0.001%时,即只要出现 1 次的项集就为频繁项集(因为实验所
用的数据集 D 的大小为 100 000)时,所测得的ρ正是按项集长度的递增而递增的.因为此时每一级长度对应的频
繁项集个数都较多,平均误差随项集长度的变化能呈现理论分析的规律.
平均支持度相对误差(%) 频繁项集丢失率(%)
频繁项集长度 k 频繁项集长度 k
−
(a) 支持度误差ρ随项集长度 k 的变化曲线 (b) 频繁项集丢失率θ 随 k 的变化曲线
频繁项集增加率(%) 平均支持度相对误差(%)
频繁项集长度 k 最小支持度阈值 min_sup
+
(c) 频繁项集增加率θ 随 k 的变化曲线 (d) 支持度误差ρ随 min_sup 的变化曲线
频繁项集丢失率(%) 频繁项集增加率(%)
最小支持度阈值 min_sup 最小支持度阈值 min_sup
−
+
(e) 频繁项集丢失率θ 随 min_sup 的变化曲线 (f) 频繁项集增加率θ 随 min_sup 的变化曲线
Fig.2 Experiment error of mask, and GR-PPFM on synthetic data
图 2 mask、GR-PPFM 在人工合成数据中的实验误差