
Page 275 - 《软件学报》2021年第12期
P. 275
郭宇红 等:分组随机化隐私保护频繁模式挖掘 3939
(1) 横向比较:横向比较图 2(d)、图 3(d)可发现:误差大小关系跟图 2(a)、图 3(a)一致,仍是 GR-PPFM<mask.
说明在整体隐私保护度相同时,多参数随机化方法 GR-PPFM 的挖掘结果优于单参数 mask 方法;
(2) 误差随支持度阈值 min_sup 的变化:观察曲线随 min_sup 的变化可发现,平均支持度误差随支持度阈
值的增大而减小.说明随着支持度阈值的增大,挖掘结果越好.原因是什么呢?由于支持度相对误差等
于绝对误差与原始支持度值的比值,假定项集 I 1 和 I 2 的绝对误差相等,则项集 I 1 和 I 2 的相对误差完全
取决于其原支持度值:原支持度值越大,其相对误差越小;原支持度值越小,其相对误差越大.当支持度
阈值增大时,其对应的频繁项集集合 F 中各项集的支持度相对越大,造成 F 中各项集的平均支持度相
对误差越小,误差随 min_sup 的变化呈现图 2(d)、图 3(d)中的趋势.
3.3.2.2 项集身份误差
图 2(e)、图 3(e)和图 2(f)、图 3(f)给出了项集身份误差随支持度阈值 min_sup 的变化情况.可看出,项集身
份误差随 min_sup 的变化跟图 2(d)、图 3(d)支持度误差ρ随 min_sup 的变化情况大体相近,其基本规律:(1) 大
多数情况下,分组随机化 GR-PPFM 方法的误差小于单参数随机化 mask 方法;(2) 误差随 min_sup 增大而减小.
−
+
θ ,θ 随 min_sup 变化规律与ρ随 min_sup 变化规律相似.
3.3.3 支持度重构与不重构误差对比
通常,数据随机化后,由于数据被扰乱,项集的支持度将发生变化,若直接从随机化后的数据挖掘,不进行支
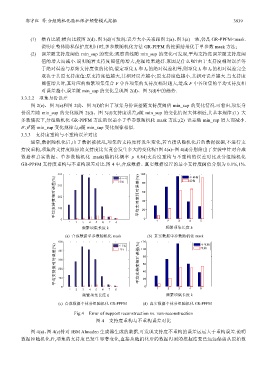
持度重构,项集的支持度跟原始支持度比究竟会发生多大的变化呢?图 4(a)~图 4(d)分别给出了实验中针对合成
数据和真实数据、单参数随机化 mask(随机化概率 p=0.84)支持度重构与不重构的误差对比及分组随机化
GR-PPFM 支持度重构与不重构误差对比.图 4 中,合成数据、真实数据设置的最小支持度阈值分别为 0.1%,1%.
100 不重构
平均支持度相对误差(%) 平均支持度相对误差(%) 60
重构
80
40
20
0 1 2 3 4 5
频繁项集长度 k 频繁项集长度 k
(a) 合成数据单参数随机化 mask (b) 真实数据单参数随机化 mask
120 不重构
平均支持度相对误差(%) 平均支持度相对误差(%) 80
重构
100
60
40
20
0
1 2 3 4 5
频繁项集长度 k 频繁项集长度 k
(c) 合成数据个体分组随机化 GR-PPFM (d) 真实数据个体分组随机化 GR-PPFM
Fig.4 Error of support reconstruction vs. non-reconstruction
图 4 支持度重构与不重构误差对比
图 4(a)、图 4(c)针对 IBM Almaden 生成器生成的数据,可发现支持度不重构的误差远远大于重构误差.说明
数据经随机化后,项集的支持度已发生显著变化,直接从随机化后的数据得到的挖掘结果已远远偏离从原始数