
Page 262 - 《软件学报》2021年第12期
P. 262
3926 Journal of Software 软件学报 Vol.32, No.12, December 2021
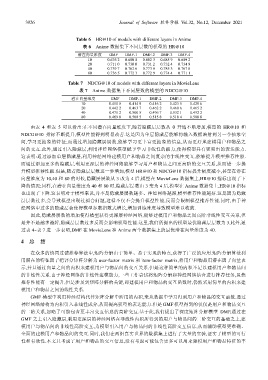
Table 6 HR@10 of models with different layers in Anime
表 6 Anime 数据集下不同层数的模型的 HR@10
潜在向量维度 GMF DMF-1 DMF-2 DMF-3 DMF-4
10 0.676 2 0.680 8 0.682 3 0.685 9 0.689 2
20 0.711 0 0.730 0 0.731 2 0.732 4 0.734 9
40 0.739 7 0.762 6 0.773 9 0.785 3 0.767 8
80 0.736 5 0.772 3 0.772 9 0.774 4 0.771 1
Table 7 NDCG@10 of models with different layers in MovieLens
表 7 Anime 数据集下不同层数的模型的 NDCG@10
潜在向量维度 GMF DMF-1 DMF-2 DMF-3 DMF-4
10 0.410 5 0.414 9 0.416 2 0.423 5 0.429 6
20 0.442 2 0.463 7 0.462 2 0.460 6 0.465 2
40 0.471 2 0.500 5 0.496 7 0.532 1 0.492 2
80 0.469 8 0.508 5 0.515 8 0.518 4 0.508 8
由表 4 和表 5 可以看出:在不同潜在向量维度下,随着隐藏层层数从 0 开始不断增加,模型的 HR@10 和
NDCG@10 指标不断提升,模型性能得到明显改善.这是因为单层隐藏层能够将输入数据映射到另一个抽象空
间,学习更抽象的特征;而通过增加隐藏层层数,能够学习更丰富更抽象的信息,从而更好地建模用户和物品之
间的交互.此外,通过引入隐藏层,利用神经网络模型赋予学习非线性的能力,使得模型具有更突出的表达能力.
这表明:通过添加单层隐藏层,利用神经网络建模用户和物品之间复杂的非线性交互,能够提升模型推荐性能.
而通过添加更多的隐藏层,利用更深层的神经网络能够学习用户和物品之间更高阶的交互关系,从而进一步提
升模型推荐性能.但是,随着隐藏层层数进一步增加,模型 HR@10 和 NDCG@10 指标提升幅度减小,甚至在潜在
向量维度为 10,40 和 80 的时候,隐藏层层数从 3 改为 4 后,模型在 MovieLens 数据集上,HR@10 指标出现了下
降的情况;同样,在潜在向量维度为 40 和 80 时,隐藏层层数由 3 变为 4 后,模型在 Anime 数据集上,HR@10 指标
也出现了下降.这表明对于模型来说,并不是隐藏层层数越多、神经网络越深,模型推荐性能越好.这是因为隐藏
层层数过多,会导致模型出现过拟合问题,这样不仅不会提升模型性能,反而会限制模型推荐性能.同时,由于神
经网络中过多的隐藏层会使得模型参数指数式增长,增加训练难度导致模型难以收敛.
因此,隐藏层层数的增加使得模型获得更深层神经网络,能够建模用户和物品之间高阶非线性交互关系,但
是并不是越多越好,隐藏层层数过多反而会影响模型性能.这里,我们所提出的模型最优隐藏层层数为 3.此外,通
过表 4~表 7 进一步表明,DMF 在 MovieLens 和 Anime 两个数据集上的最优潜在向量维度为 40.
4 总 结
在众多的协同过滤推荐算法中,矩阵分解由于简单、易于实现的特点,获得了广泛的应用.矩阵分解算法利
用潜在的特征因子把评分矩阵分解为 user-factor matrix 和 item-factor matrix,将用户和物品用潜在因子向量表
示,并且通过向量之间的内积来建模用户与物品间的交互关系.但是这种简单的内积不足以建模用户和物品间
的非线性关系.由于神经网络的非线性建模能力,一些工作尝试将矩阵分解和神经网络结合进行推荐任务,虽然
推荐性能有一定提升,但是涉及到矩阵分解的关键,即建模用户和物品的交互函数时,仍然采用简单的内积来建
模用户和物品之间的线性关系.
GMF 模型中利用神经结构代替矩阵分解中所用的内积,来从数据中学习得到用户和物品的交互函数.通过
神经网络结构为内积引入非线性成分,从而提高模型的表达能力.但是 GMF 模型得到的仅仅是用户和物品交互
的二阶关系,忽略了可能包含更丰富交互信息的高阶交互.基于此,我们提出了深度矩阵分解模型 DMF,通过在
GMF 之上引入隐藏层,利用更深层的神经网络在非线性内积所得到的用户与物品间的二阶交互的基础之上,建
模用户与物品间的非线性高阶交互,为模型引入用户与物品间的非线性高阶交互信息,从而辅助模型更准确、
全面的建模用户和物品间的交互.同时,我们在两组真实世界的数据集上进行了大量的实验,证实了模型的可行
性和有效性.本文只考虑了用户和物品的交互信息,没有考虑可能包含更多可以用来建模用户和物品特征的丰