
Page 261 - 《软件学报》2021年第12期
P. 261
田震 等:深度矩阵分解推荐算法 3925
(a) HR@10 (b) NDCG@10
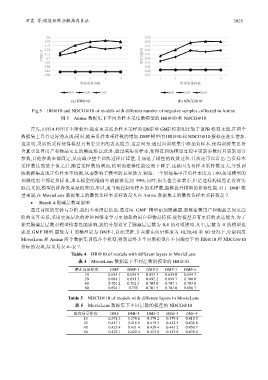
Fig.5 HR@10 and NDCG@10 of models with different number of negative samples collected in Anime
图 5 Anime 数据集下不同负样本采集数模型的 HR@10 和 NDCG@10
首先,由图 4 和图 5 不难看出:拥有更灵活负样本采样的 DMF 和 GMF 模型相比较于 BPR 模型来说,在两个
数据集上具有更好的表现;同时,随着负样本采样数的增加,DMF 模型的 HR@10 和 NDCG@10 指标在逐步增加.
这表明,灵活的采样使得模型具有更突出的表达能力.这是因为:通过向训练集中添加负样本,使得训练集更符
合真实世界用户和物品交互的稀疏场景;此外,通过采集负样本,使得在训练模型过程中更新参数时只更新部分
参数,其他参数全部固定,从而减少整个训练过程计算量,并加速了模型的收敛过程.其次还可以看出:当负样本
采样数达到某个值之后,随着采样数的增加,模型的推荐性能反而下降了.这是因为负样本采样数过大,导致训
练数据集出现正负样本不均衡,从而影响了模型的表现能力.例如:一个训练集中正负样本比为 1:99,如果模型的
预测结果全都是负样本,那么模型的准确率就能够达到 99%;同时,损失值会非常小,但是这样的模型是没有实
际意义的,模型的推荐效果是很差的.所以,适当地控制负样本的采样数,能够提升模型的推荐性能.对于 DMF 模
型来说,在 MovieLens 数据集上的最优负样本采样数是 5,在 Anime 数据集上的最优负样本采样数是 7.
• Result 4:隐藏层数量影响
通过前面的实验与分析,我们不难得出结论:通过向 GMF 模型添加隐藏层,能够建模用户和物品之间更高
阶的交互关系,采用更深层次的神经网络来学习更抽象的用户和物品特征,使得模型具有更好的表达能力.为了
探究隐藏层层数对模型推荐性能影响,我们分别设置了隐藏层层数为 0,4 的对照模型,其中,层数为 0 的模型也
就是 GMF 模型,层数为 1 的模型记为 DMF-1,以此类推,并在潜在向量维度为 10,20,40 和 80 情况下,分别利用
MovieLens 和 Anime 两个数据集训练各个模型,得到最终 5 个对照模型在不同维度下的 HR@10 和 NDCG@10
指标的表现,结果见表 4~表 7.
Table 4 HR@10 of models with different layers in MovieLens
表 4 MovieLens 数据集下不同层数的模型的 HR@10
潜在向量维度 GMF DMF-1 DMF-2 DMF-3 DMF-4
10 0.654 1 0.654 9 0.653 3 0.655 0 0.654 3
20 0.684 1 0.691 3 0.692 2 0.699 7 0.700 0
40 0.701 2 0.702 3 0.705 0 0.707 1 0.703 8
80 0.694 1 0.700 0.701 5 0.703 0 0.696 7
Table 5 NDCG@10 of models with different layers in MovieLens
表 5 MovieLens 数据集下不同层数的模型的 NDCG@10
潜在向量维度 GMF DMF-1 DMF-2 DMF-3 DMF-4
10 0.378 3 0.378 6 0.379 2 0.379 8 0.419 5
20 0.417 1 0.418 9 0.419 5 0.422 5 0.438 8
40 0.423 4 0.431 4 0.429 4 0.443 2 0.450 7
80 0.422 1 0.422 4 0.423 8 0.435 8 0.436 0