
Page 267 - 《软件学报》2021年第12期
P. 267
郭宇红 等:分组随机化隐私保护频繁模式挖掘 3931
不同.本文理论上推导了支持度重构递归公式,基于递归公式设计了完整的分组随机化隐私保护频繁项集挖掘
算法,并基于大规模合成和真实数据集,针对支持度重构误差和隐私保护性能,与已有的 mask,emask,RE 方法进
行了实验对比和评价,验证了方法的有效性.
事实上,隐私保护的内涵决定了其首要目标是为个体提供其所要求的保护,而差异化保护正体现了这一内
在目标.GR-PPFM 可在兼顾这种差异化保护要求的同时,保证正常挖掘任务的执行.实验结果表明:相对于已有
单参数随机化 mask 方法,GR-PPFM 不仅能满足不同群体多样化的隐私保护需求,加强随机化参数设置的灵活
性,还能在整体隐私保护度相同情况下,提高挖掘结果准确性.
1 问题与架构
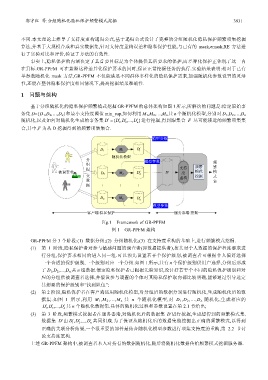
基于分组随机化的隐私保护频繁模式挖掘 GR-PPFM 的总体架构如图 1 所示,所解决的问题是:给定原始事
务集 D={D 1 ,D 2 ,…,D n }和最小支持度阈值 min_sup,如何利用 M 1 ,M 2 ,…,M n 共 n 个随机化模型,分别对 D 1 ,D 2 ,…,D n
随机化,以及如何对随机化生成的事务集 D′ = {,D D′ ′ ,...,D′ }进行挖掘,得到跟集合 F 尽可能接近的频繁项集集
1 2 n
合,其中,F 为从 D 挖掘得到的频繁项集集合.
模型参数
D 1 M 1 1 D′
随机化模型
分 模型参数
组 频
... 提 支持 频繁 繁
被调查者 M 2 D′ D′ 度 模式 模
交 D 2 2 重构 挖掘 式
数 集
据 ... ... ...
D n M n D′ n
模型参数
客户端:隐私保护 服务器端:挖掘
Fig.1 Framework of GR-PPFM
图 1 GR-PPFM 架构
GR-PPFM 分 3 个阶段:(1) 数据分组;(2) 分组随机化;(3) 在支持度重构的基础上,进行频繁模式挖掘.
(1) 第 1 阶段,隐私保护者对参与敏感问题的调查者(即数据提供者),按其对个人数据的保护程度要求进
行分组,保护要求相同的进入同一组.可以预先设置若干个保护级别,被调查者可根据个人偏好选择
一个合适的保护级别,一个级别对应一个分组.如图 1 所示,共有 n 个保护级别供用户选择,分组后形成
了 D 1 ,D 2 ,…,D n 共 n 组数据.假定隐私保护者已根据先验知识,设计好若干个不同的隐私保护级别和对
应的分组供被调查者选择,并假设参与调查的个体对其隐私保护取向都比较明确,能够通过引导选定
其想要的保护级别和“找到队伍”;
(2) 第 2 阶段,隐私保护者在客户端运用随机化模型,对分组后的数据分别进行随机化,生成随机化后的数
据集.如图 1 所示,利用 M 1 ,M 2 ,…,M n 共 n 个随机化模型,对 D 1 ,D 2 ,…,D n 随机化,生成相应的
DD′ 1 , ′ 2 ,...,D′ n 共 n 个随机化数据集.具体的随机化过程和参数设置在第 2.1 节给出;
(3) 第 3 阶段,频繁模式挖掘者在服务器端,对随机化后的数据集 D′进行挖掘,生成想得到的频繁模式集.
数据集 D′由 DD′ 1 , ′ 2 ,...,D′ n 共同组成.为了保证从随机化后的数据集能挖掘出正确的频繁模式,以得到
正确的关联分析结果,一个很重要的部件是结合随机化模型参数进行项集支持度的重构,第 2.2 节讨
论支持度重构.
上述 GR-PPFM 架构中,被调查者本人对持有的数据随机化,随后将随机化数据传给频繁模式挖掘服务器.