
Page 73 - 《软件学报》2021年第11期
P. 73
赵时海 等:用户群体满意度最大化的 Top-k 在线服务评价 3399
础上进行处理.首先要将每次迭代得到的在线服务与其对应的用户进行分配,然后采用本文的用户满意度计算
方法计算所选服务对应的用户满意度,最后叠加 k 个在线服务对应用户的满意度分数构成用户群体满意度.
*
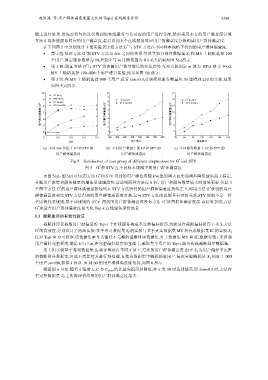
在下列图 5 中分别设计 3 组实验来比较方法 G 与 STV 方法在不同样本规模下得到的用户群体满意度.
*
• 第 1 组:验证方法 G 和 STV 方法与 k/m 之间的关系.每次实验分别在数据集 S 1 和 MV 上随机选择 100
个用户,固定服务数量为 10,控制 k 与 m 比例范围为 0.1~0.5,结果如图 5(a)所示.
*
• 第 2 组:验证方法 G 与 STV 方法随用户数量增长的变化趋势.每次实验固定 m 值为 100,k 值为 30,在
MV 上随机选择 100~800 个用户进行实验,结果如图 5(b)所示.
• 第 3 组:在 MV 上随机选择 900 个用户,设置 k/m=0.3,分别模拟服务数量从 30 递增到 210 的实验,结果
如图 5(c)所示.
10 10 21
G* for S 1
9
9 STV for S 1 G for MV 18 G for MV
*
*
G* for MV 8 7 STV for MV 15 STV for MV
用户群体满意度×10 2 7 6 用户群体满意度×10 4 6 5 4 3 用户群体满意度×10 4 12 9
STV for MV
8
4 5 2 1 6 3
0
0.1 0.2 0.3 0.4 0.5 100 200 300 400 500 600 700 800 30 60 90 120 150 180 210
k/m 用户数量 服务数量
(a) 不同 k/m 比值下 G*和 STV 的 (b) 不同用户数量下的 G*和 STV 的 (c) 不同服务数量下 G*和 STV 的
用户群体满意度 用户群体满意度 用户群体满意度
*
Fig.5 Satisfaction of user group of different simple sizes for G and STV
*
图 5 G 和 STV 在不同样本规模下的用户群体满意度
*
由图 5(a)~图 5(c)可知,用方法 G 和 STV 得到的用户满意度随 k/m 值的增大而先递增后降低最后趋于稳定,
并随用户数量和服务数量的增加呈递增趋势.这说明两种方法在 k 值、用户和服务数量较大时效果更好.但是 3
*
*
个图中方法 G 的用户群体满意度折线均在 STV 方法所得的用户群体满意度折线之上,即用方法 G 获得的用户
群体满意度要比 STV 方法得到的用户群体满意度更高.这与 STV 方法的思想具有密切关系.STV 规则不是一种
*
全比例代表规则,基于该规则的 STV 得到的用户群体满意度没有方法 G 所得群体满意度高.该结果表明,方法
*
G 更适合用户群体满意度最大化 Top-k 在线服务评价场景.
5.3 截断排序的有效性验证
截断排序仅截取用户最偏爱的 Top-t 个在线服务构成不完整偏好排序.为验证在截断偏好排序下本文方法
*
G 的有效性,分别设计了两组实验:基于寿司数据集 S 2 的实验与基于真实数据集 MV 和合成数据集 IC 的实验.S 2
仅对 Top-10 寿司排序,该数据集本身为偏好不完整的截断排序数据集.对于数据集 MV 和 IC,根据参数 t 来控制
用户偏好完整程度,满足 k≤t≤m,在完整偏好排序的基础上,截取每个用户的 Top-t 服务构成截断排序数据集.
第 1 组实验基于寿司数据集 S 2 验证算法在不同 k 值下,方法的用户群体满意度.由于 S 2 为用户偏好不完整
的截断排序数据集,因此不需要对其进行预处理,直接从数据集中随机抽取用户.每次实验随机从 S 2 抽取 1 000
个用户,m=100,模拟 k 值从 10 到 60 的用户群体满意度情况,如图 6 所示.
根据图 6 可知,随着 k 值增大,C 与 C ideal 的比值先提高后降低,在 k 为 30 时达到最高.即 k/m=0.3 时,方法在
不完整数据集 S 2 上所得评价结果的用户群体满意度最大.