
Page 160 - 《软件学报》2021年第11期
P. 160
3486 Journal of Software 软件学报 Vol.32, No.11, November 2021
I
给定标注的源域图像数据 S={I,Y }以及未标注的目标域视频数据 T={V}.其中,I 和 V 分别表示图像数据和
I
视频数据,Y 表示图像数据的类别标签.由于域差异和模态差异,源域图像数据和目标域视频数据具有不同的数
据分布,这导致从源域数据中学习到的知识很难直接应用于目标域数据.本文的目标是通过降低图像和视频之
间跨域、跨模态的数据分布差异,进而在无监督条件下学习得到目标域视频数据的分类器.
2.2 无监督辨识适应网络
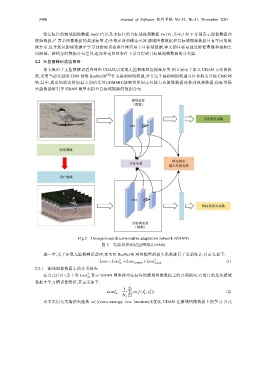
本文提出了无监督辨识适应网络 UDAN,以实现无监督细粒度视频分类.图 2 展示了本文 UDAN 方法的框
架,采用当前先进的 CNN 网络 ResNet50 [20] 作为基础网络模型,并且这个基础网络模型可以替换为其他 CNN 网
络.其中,提出的联合辨识最大均值差异(JDMMD)能够将辨识定位能力从图像数据迁移到视频数据,伪标签损
失函数能够引导 UDAN 模型来拟合目标域视频的数据分布.
Fig.2 Unsupervised discriminative adaptation network (UDAN)
图 2 无监督辨识适应网络(UDAN)
进一步,为了实现无监督辨识适应,本文对 ResNet50 网络模型的损失函数进行了重新设计,其定义如下:
Loss = Loss + S Loss + Loss T (1)
cls JDMMD pseudo
2.2.1 源域图像数据上的分类损失
S
在公式(1)中,第 1 项 Loss 表示 UDAN 网络模型在标注的源域图像数据上的分类损失,它的目的是从源域
cls
数据中学习辨识性特征,其定义如下:
1 N S
S
,
Loss S cls = ∑ ce (( f x y S k )) (2)
k
N S k = 1
本文采用交叉熵损失函数 ce(⋅)(cross-entropy loss function)来优化 UDAN 在源域图像数据上的学习.公式