
Page 99 - 《软件学报》2021年第9期
P. 99
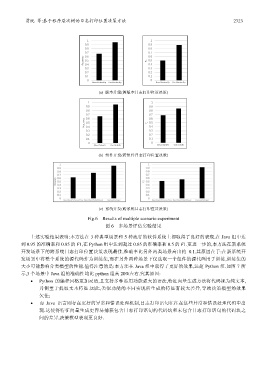
贾统 等:基于程序层次树的日志打印位置决策方法 2723
(a) 版本升级(跨版本日志打印位置决策)
(b) 组件开发(跨组件日志打印位置决策)
(c) 系统开发(跨系统日志打印位置决策)
Fig.6 Results of multiple scenario experiment
图 6 多场景评估实验结果
上述实验结果表明:本方法在 3 种典型场景和 5 种流行的软件系统上都取得了良好的表现,在 Java 组中达
到 0.95 的准确率和 0.85 的 F1,在 Python 组中达到超过 0.65 的准确率和 0.5 的 F1.更进一步的,本方法在新系统
开发场景下的跨系统日志打印位置决策表现最佳,准确率比另外两类场景高出约 0.1.其原因在于:在新系统开
发场景中将整个系统的源代码作为训练集,而在另外两种场景下仅选取一个组件的源代码用于训练,训练集的
大小可能影响分类模型的性能.值得注意的是:本方法在 Java 组中取得了更好的效果,远超 Python 组.如图 7 所
示,3 个场景中 Java 组的准确性均比 python 组高 20%左右.究其原因:
• Python 的编程风格更加灵活,且支持多种易用功能强大的语法,特征向量生成方法将代码视为纯文本,
并侧重于提取文本特征.因此,类似功能的不同实现所生成的特征有较大差异,导致决策模型的效果
欠佳;
• 而 Java 语言则存在更好的异常和错误处理机制,日志打印语句往往在这些异常和错误处理代码中出
现.这使得特征向量生成更容易捕获包含日志打印语句的代码块和未包含日志打印语句的代码块之
间的差异,决策模型表现更良好.