
Page 101 - 《软件学报》2021年第9期
P. 101
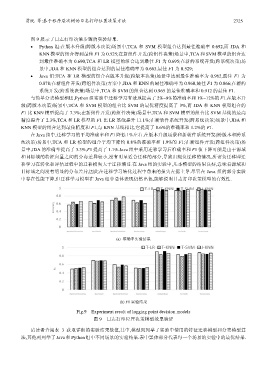
贾统 等:基于程序层次树的日志打印位置决策方法 2725
图 9 展示了日志打印决策步骤的实验结果.
• Python 组:在版本升级(跨版本决策)场景中,TCA 和 SVM 模型组合达到最佳准确率 0.692,而 JDA 和
KNN 模型的组合得到最佳 F1 为 0.525;在新组件开发(跨组件决策)场景中,TCA 和 SVM 模型的组合达
到最佳准确率为 0.690,TCA 和 LR 模型的组合达到最佳 F1 为 0.695;在新的系统开发(跨系统决策)场
景中,JDA 和 KNN 模型的组合达到的最佳准确率为 0.663,最佳 F1 为 0.529;
• Java 组:TCA 和 LR 模型的组合在版本升级(跨版本决策)场景中达到最佳准确率为 0.962,最佳 F1 为
0.878;在新组件开发(跨组件决策)方案中,JDA 和 KNN 的最佳准确率为 0.960,最佳 F1 为 0.866;在新的
系统开发(跨系统决策)场景中,TCA 和 SVM 的组合达到 0.965 的最佳准确率和 0.912 的最佳 F1.
与简单分类模型相比,Python 组实验中迁移学习有效地提高了 2%~9%的准确率和 1%~12%的 F1.在版本升
级(跨版本决策)场景中,TCA 和 SVM 模型的组合比 SVM 的最优精度提高了 3%,而 JDA 和 KNN 模型组合的
F1 比 KNN 模型提高了 7.3%;在新组件开发(跨组件决策)场景中,TCA 和 SVM 模型的组合比 SVM 基线的最高
精度提升了 2.3%,TCA 和 LR 模型的 F1 比 LR 基线提升 11.1%;在新软件系统开发(跨系统决策)场景中,JDA 和
KNN 模型的组合达到最佳精度和 F1,与 KNN 基线相比,它提高了 8.6%的准确率和 1.2%的 F1.
在 Java 组中,迁移学习的平均准确率和 F1 降低 1%左右.在版本升级场景和新软件系统开发(跨版本和跨系
统决策)场景中,TCA 和 LR 模型的组合平均下降约 0.8%的准确率和 1.9%的 F1;在新组件开发(跨组件决策)场
景中,JDA 的准确率提高了 3.3%,F1 提高了 1.1%.Java 组中采用迁移学习后准确率和 F1 值下降可能是由于源域
和目标域的特征向量之间的分布差异较小,没有明显适合迁移的部分,导致出现负迁移的情况.所谓负迁移即迁
移学习在转化和评估过程中的迁移损失大于迁移增益.在 Java 组的实验中,基本模型的结果良好,意味着源域和
目标域之间没有明显的分布差异,因此在迁移学习转化过程中带来的损失占据主导.尽管在 Java 组的部分实验
中存在性能下降,但迁移学习模型在 Java 组中总体表现仍然出色,能够说明日志打印决策模型的有效性.
(a) 准确率实验结果
(b) F1 实验结果
Fig.9 Experiment result of logging point decision models
图 9 日志打印位置决策模型效果验证
请读者查阅表 3 获取详细的实验结果数值,其中,模型列列举了实验中使用的特征迁移模型和分类模型算
法,其他列列举了 Java 和 Python 组中不同场景的实验结果.表中黑体部分代表每一个场景的实验中的最优结果.