
Page 102 - 《软件学报》2021年第9期
P. 102
2726 Journal of Software 软件学报 Vol.32, No.9, September 2021
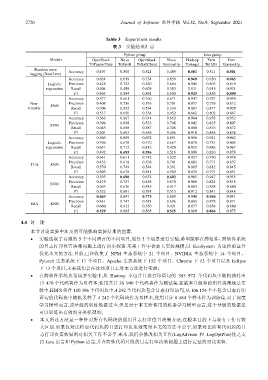
Table 3 Experiment results
表 3 实验结果汇总
Python group Java group
Models OpenStack Nova OpenStack Nova Hadoop Yarn Yarn
ToTensorFlow ToSwift ToSaltCloud VersionUp ToAngel ToHdfs VersionUp
Random error Accuracy 0.497 0.500 0.521 0.489 0.511
logging (BaseLine) 0.501 0.501
Accuracy 0.624 0.619 0.734 0.659 0.969 0.950 0.965
Logistic Precision 0.428 0.723 0.520 0.684 0.941 0.805 0.819
regression Recall 0.504 0.489 0.609 0.393 0.911 0.915 0.974
F1 0.463 0.584 0.561 0.500 0.925 0.856 0.890
Accuracy 0.577 0.661 0.760 0.671 0.947 0.927 0.959
Non- Precision 0.408 0.736 0.576 0.701 0.857 0.739 0.812
transfer KNN Recall 0.706 0.592 0.534 0.334 0.867 0.877 0.929
F1 0.517 0.656 0.554 0.452 0.862 0.802 0.867
Accuracy 0.563 0.667 0.741 0.662 0.964 0.952 0.952
Precision 0.396 0.698 0.533 0.748 0.942 0.835 0.807
SVM
Recall 0.685 0.688 0.587 0.328 0.880 0.876 0.872
F1 0.501 0.693 0.559 0.456 0.910 0.855 0.838
Accuracy 0.569 0.659 0.692 0.691 0.956 0.941 0.962
Logistic Precision 0.396 0.678 0.470 0.667 0.876 0.781 0.805
regression Recall 0.651 0.712 0.813 0.420 0.921 0.886 0.967
F1 0.492 0.695 0.596 0.516 0.898 0.830 0.878
Accuracy 0.641 0.611 0.742 0.622 0.927 0.930 0.958
Precision 0.453 0.619 0.538 0.701 0.802 0.771 0.857
TCA KNN
Recall 0.570 0.749 0.544 0.391 0.865 0.812 0.845
F1 0.505 0.678 0.541 0.502 0.832 0.791 0.851
Accuracy 0.593 0.690 0.674 0.692 0.965 0.947 0.955
Precision 0.419 0.757 0.455 0.670 0.966 0.824 0.818
SVM
Recall 0.693 0.636 0.845 0.417 0.863 0.858 0.880
F1 0.522 0.691 0.591 0.515 0.912 0.841 0.848
Accuracy 0.663 0.647 0.773 0.609 0.940 0.960 0.941
Precision 0.441 0.747 0.581 0.696 0.861 0.878 0.871
JDA KNN
Recall 0.660 0.633 0.550 0.421 0.877 0.854 0.880
F1 0.529 0.685 0.565 0.525 0.869 0.866 0.875
4.4 讨 论
本节讨论实验中涉及的可能影响实验结果的因素.
• 实验选取了有限的 5 个不同语言的不同项目,划分 3 个场景进行实验,希望能够在跨组件、跨软件系统
的日志打印位置决策问题上进行初步探索.未来工作中会加大实验规模,以 EcoSystem 为单位验证并
优化本文的方法.目前,已经收集了 NPM 生态系统中 21 个项目、NVIDIA 生态系统中 14 个项目、
Pytorch 生态系统下 17 个项目、Apache 生态系统下 152 个项目、Chrome 下 13 个项目以及 Eclipse
下 13 个项目,未来我们会在这些项目上对本方法进行实验;
• 在跨软件系统决策场景实验中,从 Hadoop 不包含日志打印语句的 383 972 个代码块中随机抽样出
13 470 个代码块作为负样本,使用共计 26 940 个代码块作为测试集.在版本升级和跨组件决策场景实
验中,HDFS 组件 110 396 个代码块中,4 242 个代码块包含日志打印语句,从 106 154 个不包含日志打印
语句的代码块中随机采样了 4 242 个代码块作为负样本,使用共计 8 484 个样本作为训练集.对于深度
学习模型而言,该量级的训练数据过少,但是对于本文所使用的机器学习模型而言,这个量级的数据是
可以训练出有效的分类模型的;
• 本文所述方法是一种针对所有代码块的通用日志打印位置决策方法,在根本目的上与现有工作有较
大区别.如果仅对比特定代码块的日志打印决策效果对本文的方法不公平,如果对比所有代码块的日
志打印决策效果则对相关工作不公平.未来,我们会修改相关工作(LogAdvisor 和 LogOptPlus)使之支
持 Java 语言和 Python 语言,并在特殊代码片段的日志打印决策问题上进行定量的对比实验.